도메인 분리 네트워크를 활용한 무지도 음성 인식 적응
본 논문은 청정 음성으로 학습된 DNN‑HMM 모델을 라벨이 없는 잡음 환경 데이터에 적응시키기 위해, 공유(공통) 특성과 도메인 전용(프라이빗) 특성을 동시에 학습하는 도메인 분리 네트워크(DSN)를 제안한다. 공유 특성은 어휘(센노) 구분 능력을 유지하면서 도메인 불변성을 확보하도록 적대적 학습으로 강화하고, 프라이빗 특성은 공유 특성과 직교하도록 제약한다. 재구성 손실을 추가해 두 특성의 정보를 보존한다. CHiME‑3 실험에서 기존 Gr…
저자: Zhong Meng, Zhuo Chen, Vadim Mazalov
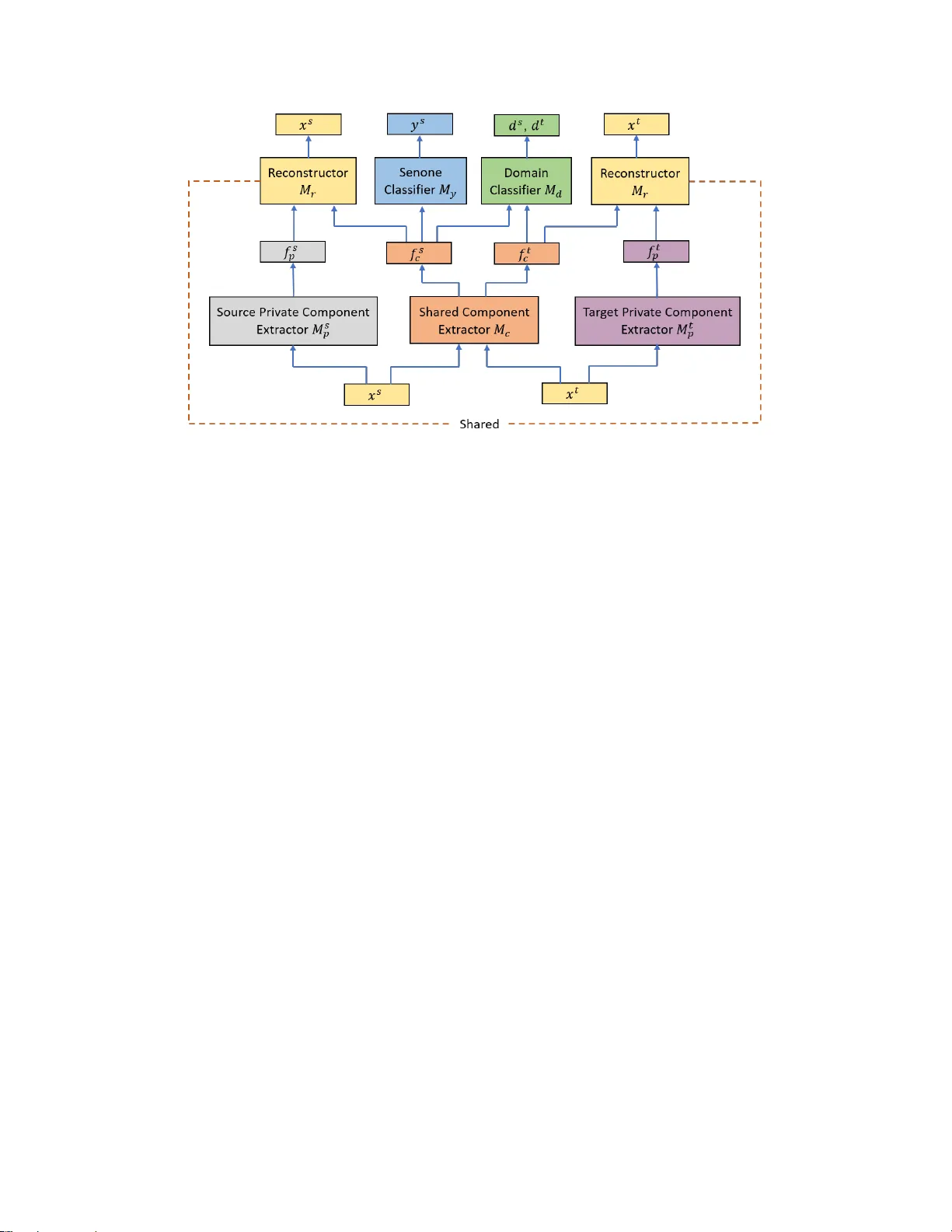
본 연구는 청정 음성으로 사전 학습된 DNN‑HMM 기반 음성 인식 모델을 라벨이 없는 잡음 환경 데이터에 효과적으로 적응시키기 위한 새로운 무지도 도메인 적응 프레임워크인 도메인 분리 네트워크(Domain Separation Networks, DSN)를 제안한다. 기존의 적대적 학습 방식, 특히 Gradient Reversal Layer(GRL)를 이용한 방법은 공유(공통) 특성만을 학습해 도메인 불변성을 확보하려 했지만, 각 도메인 고유의 정보를 무시한다는 한계가 있었다. 이를 보완하기 위해 DSN은 입력 음성 프레임을 두 개의 잠재 표현, 즉 ‘공유 컴포넌트’와 ‘프라이빗 컴포넌트’로 분리한다.
공유 컴포넌트는 기존 GRL과 유사하게 senone(음소 상태) 분류와 도메인 분류라는 두 과업을 동시에 수행한다. 도메인 분류기의 손실을 역전시켜(gradient reversal) 공유 컴포넌트가 도메인 구분이 어려운 표현을 만들도록 유도함으로써, 공유 컴포넌트가 도메인 불변성을 갖도록 학습한다. 동시에 senone 분류 손실을 최소화해 공유 컴포넌트가 음성 인식에 필요한 discriminative 정보를 유지하도록 한다.
프라이빗 컴포넌트는 각각 소스와 타깃 도메인에 대해 별도의 DNN(소스 프라이빗 추출기와 타깃 프라이빗 추출기)으로 추출된다. 이 프라이빗 컴포넌트는 공유 컴포넌트와 직교하도록 제약함으로써, 두 특성이 서로 중복되지 않게 만든다. 직교 제약은 두 컴포넌트 간의 내적을 최소화하는 형태의 손실(L_diff)로 구현되며, 이는 공유 컴포넌트가 더욱 순수하게 도메인 불변 정보를 담게 하는 역할을 한다.
또한, 공유와 프라이빗 컴포넌트를 결합해 원본 음성 특성을 복원하는 재구성 네트워크(M_r)를 도입한다. 재구성 손실(L_recon)은 평균 제곱 오차(MSE) 형태로 정의되어, 두 컴포넌트가 원본 정보를 충분히 보존하도록 정규화한다. 재구성 손실은 전체 손실에 가중치 γ를 부여해 학습 과정에서 과적합을 방지하고, 프라이빗·공유 컴포넌트가 의미 있는 표현을 학습하도록 돕는다.
전체 손실 함수는 다섯 개의 항목으로 구성된다.
1) senone 분류 손실 L_senone – senone 라벨이 있는 청정 데이터에 대해 교차 엔트로피 최소화.
2) 도메인 분류 손실 L_d_domain – 도메인 라벨(소스/타깃) 예측을 위한 교차 엔트로피 최소화.
3) 공유 컴포넌트에 대한 도메인 손실 L_c_domain – 역전된 그래디언트(−α)를 통해 도메인 분류 손실을 최대화, 즉 공유 컴포넌트가 도메인 구분이 어려운 표현을 만들도록 유도.
4) 직교 손실 L_diff – 공유와 프라이빗 컴포넌트 간의 직교성을 강제.
5) 재구성 손실 L_recon – 원본 특성 복원을 통한 정규화.
각 손실에 대한 가중치 α, β, γ는 실험적으로 조정되며, 최적화는 확률적 경사 하강법(SGD) 기반 역전파로 수행된다. 특히 공유 컴포넌트 파라미터 업데이트 시 ‘-α’가 곱해진 역전파가 적용돼, 도메인 분류기의 손실을 최대화하는 효과를 만든다. 이는 기존 GRL 구현과 동일한 역할을 수행한다.
실험은 3rd CHiME 챌린지에서 제공한 CHiME‑3 데이터셋을 사용했다. 데이터는 청정 음성(WSJ0 SI‑85)과 4가지 실제 잡음 환경(버스, 카페, 보행자 길, 거리) 및 시뮬레이션 잡음으로 구성된다. 학습에 사용된 청정 데이터는 8738 utterance이며, 동일한 양의 잡음 데이터가 타깃 도메인으로 제공된다. 입력 특성은 29차원 로그 멜 필터뱅크에 1차·2차 델타를 추가해 87차원, 전후 5프레임을 스플라이스해 957차원으로 만든다. DNN 구조는 7개의 은닉층(각 2048 유닛)과 3012개의 senone 출력 유닛을 가진다.
베이스라인은 청정 DNN‑HMM을 GRL 방식으로 무지도 적응한 모델이다. 이 모델은 청정 데이터에 대해 사전 학습된 뒤, 라벨이 없는 잡음 데이터에 대해 GRL을 적용해 도메인 불변 특성을 학습한다. 제안된 DSN은 동일한 초기화 조건에서 학습되었으며, 추가적인 프라이빗 추출기와 재구성 네트워크가 포함된다.
실험 결과, DSN은 GRL 기반 베이스라인 대비 평균 11.08% 상대 WER 감소를 달성했다. 특히 실제 잡음 환경에서 더 큰 개선을 보였으며, 시뮬레이션 잡음에서도 일관된 성능 향상을 기록했다. 이는 프라이빗 컴포넌트를 명시적으로 모델링하고 공유 컴포넌트와 직교시키는 것이 도메인 불변성을 강화하고, 재구성 손실이 과적합을 방지해 전체 시스템의 일반화 능력을 높였기 때문이다. 또한, 병렬 데이터나 타깃 라벨이 전혀 없는 상황에서도 효과적으로 적응할 수 있어, 실시간 서비스나 프라이버시 제한이 있는 경우에도 적용 가능성을 시사한다.
결론적으로, 본 논문은 무지도 음성 인식 적응에 있어 ‘공유 vs 프라이빗’ 특성 분리를 통한 새로운 설계 패러다임을 제시함으로써, 기존 적대적 학습의 한계를 보완하고 더 견고한 도메인 일반화 성능을 달성했다는 점에서 학술적·실용적 의의가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기