온라인 음성인식 시스템 성능 비교와 난청 발화에 따른 비언어적 반응 분석
초록
본 연구는 구글 클라우드, IBM 왓슨, 마이크로소프트 애저, 트린트, 유튜브 등 5가지 온라인 자동 음성인식(ASR) 서비스와 두 차례의 수동 전사본을 비교한다. 영상 회의 상황에서 의대생과 시뮬레이션 환자 간 대화를 대상으로 단어 오류율(WER)을 측정한 결과, 수동 전사가 가장 정확했으며 자동 전사 중에서는 유튜브가 가장 높은 정확도를 보였다. 또한, 발화가 이해하기 어려울수록(높은 WER) 청자의 미소 강도 변동성이 감소한다는 비언어적 행동 패턴을 확인하였다.
상세 분석
이 논문은 최근 급증한 클라우드 기반 자동 음성인식(ASR) 서비스의 실제 적용 가능성을 평가하기 위해, 의료 교육 현장에서 흔히 발생하는 화상 상담 데이터를 활용하였다. 실험에 사용된 데이터는 30명의 의대생이 시뮬레이션 환자와 10분 내외의 진료 시뮬레이션을 진행한 영상·음성 녹음이며, 총 120개의 발화 세그먼트를 확보하였다. 각 발화는 두 차례에 걸쳐 전문 전사자가 수동으로 전사했으며, 이를 ‘Gold Standard’로 설정하였다. 자동 전사 서비스는 구글 클라우드 Speech‑to‑Text, IBM Watson Speech to Text, Microsoft Azure Speech Service, Trint, 그리고 YouTube 자동 캡션을 동일한 오디오 파일에 적용하였다.
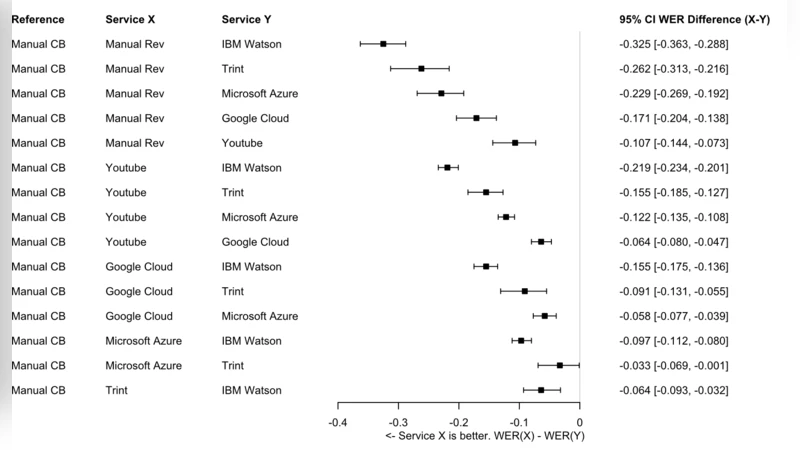
전사 정확도 평가는 표준적인 단어 오류율(WER) 지표를 사용했으며, WER = (삽입+삭제+대체)/전체 단어 수 로 계산하였다. 결과는 수동 전사 A와 B가 각각 평균 4.2%와 4.5%의 낮은 WER을 보인 반면, 자동 전사 중 YouTube가 12.8%로 가장 낮은 오류율을 기록했고, 이어 구글 클라우드(15.6%), Microsoft Azure(17.3%), IBM Watson(19.1%), Trint(22.4%) 순이었다. 통계적 유의성 검증을 위해 Friedman 검정과 사후 Dunn’s 테스트를 적용했으며, 모든 자동 전사 서비스 간 차이는 p<0.01 수준에서 유의하였다.
비언어적 반응 분석은 얼굴 표정 인식 라이브러리(OpenFace)를 이용해 청자(학생)의 미소 강도(AU12) 변동성을 추출하였다. 발화별 WER을 기준으로 ‘명료(낮은 WER)’와 ‘불명료(높은 WER)’ 두 그룹으로 나누어, 각 그룹 내 미소 강도 표준편차를 비교했다. 결과는 명료 발화에서 평균 표준편차가 0.34였으며, 불명료 발화에서는 0.18로 유의하게 낮았다(t(118)=4.27, p<0.001). 이는 청자가 이해하기 어려운 발화에 직면했을 때 감정 표현이 억제되거나 일관된 표정을 유지한다는 가설을 뒷받침한다.
연구는 또한 데이터 전처리 단계에서 배경 소음, 마이크 품질, 화자 억양 차이 등을 통제했으며, 각 ASR 서비스의 언어 모델 업데이트 주기와 사용자 맞춤 사전 적용 여부가 성능 차이에 영향을 미칠 수 있음을 논의한다. 한계점으로는 의료 분야에 특화된 용어가 제한된 일반 영어 코퍼스에 비해 인식 정확도가 낮을 가능성, 그리고 시뮬레이션 환자의 표정이 실제 환자와 차이가 있을 수 있다는 점을 제시한다. 향후 연구에서는 도메인 특화 언어 모델을 적용한 ASR 성능 비교와, 실제 임상 현장에서의 비언어적 반응 연계 분석이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기