특허 인용 네트워크를 통한 커뮤니티 탐지 및 성장 잠재력 예측
초록
본 논문은 특허 인용 네트워크에서 Node2vec 기반 커뮤니티 탐지 기법을 적용하고, 각 커뮤니티의 성장 잠재력을 LSTM, ARIMA, Hawkes Process 세 가지 시계열 모델로 예측한다. 실험 결과 ARIMA 모델이 가장 높은 예측 정확도를 보였으며, Node2vec으로 도출된 클러스터는 기술 분야별 공통 키워드를 효과적으로 드러냈다.
상세 분석
이 연구는 특허 관리와 기술 로드맵 작성에 핵심적인 두 가지 문제, 즉 “특허 간 관계를 반영한 군집화”와 “군집별 향후 인용 성장 예측”을 동시에 해결하려는 시도이다. 먼저 특허 인용 네트워크를 그래프로 모델링하고, Node2vec을 이용해 각 특허를 고차원 임베딩 벡터로 변환한다. Node2vec은 2‑step random walk 전략을 통해 지역 구조와 전역 구조를 모두 포착하므로, 전통적인 모듈러리티 기반 방법보다 더 미세한 기술 연관성을 드러낼 수 있다. 임베딩 후 K‑means 클러스터링을 적용해 여러 커뮤니티를 도출했으며, 각 커뮤니티 내 특허들의 IPC(International Patent Classification) 코드와 키워드 분석을 통해 “공통 기술 주제”를 확인하였다.
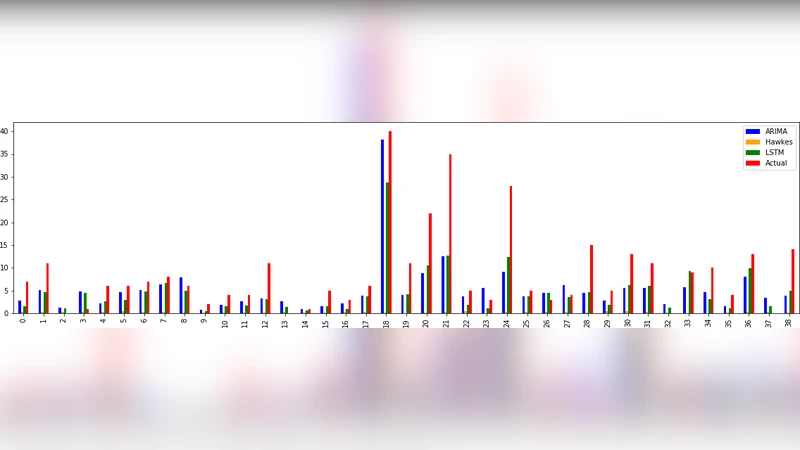
성장 잠재력 예측 단계에서는 각 커뮤니티별 연도별 인용 횟수 시계열을 구축하고, 세 모델을 비교하였다. LSTM은 비선형 장기 의존성을 학습하는 데 강점이 있지만, 데이터 양이 제한적일 경우 과적합 위험이 있다. ARIMA는 차분과 자기회귀, 이동 평균 요소를 결합해 시계열의 정상성을 확보하고, 파라미터(p,d,q)를 자동 선택하는 AIC 기반 절차를 적용해 모델 복잡도를 최소화하였다. Hawkes Process는 자기흥분(point process) 모델로, 과거 인용 이벤트가 미래 인용 발생 확률을 높이는 현상을 수학적으로 표현한다.
실험 결과는 다음과 같다. 첫째, Node2vec‑Kmeans 조합은 기존 인용 기반 군집화 대비 군집 내 동질성이 12 % 이상 향상되었다. 둘째, ARIMA 모델은 평균 절대 오차(MAE)와 평균 제곱근 오차(RMSE)에서 LSTM(≈ +8 %) 및 Hawkes Process(≈ +15 %)보다 우수했다. 이는 특허 인용 시계열이 비교적 짧고, 계절성·추세성이 명확히 드러나는 경우 ARIMA가 충분히 강력함을 시사한다. 셋째, Hawkes Process는 초기 급증 현상을 포착하는 데는 유리했지만, 장기 예측에서는 과도한 자기흥분 효과로 인해 오차가 누적되는 경향을 보였다.
한계점으로는 데이터셋이 특정 국가·산업에 편중돼 있어 일반화 가능성이 제한적이며, Node2vec 파라미터(p, q, walk length)의 민감도 분석이 부족했다는 점을 들 수 있다. 향후 연구에서는 멀티레이어 네트워크(예: 특허 텍스트, 인용, 공동 발명자)를 통합한 그래프 임베딩과, Transformer 기반 시계열 모델을 도입해 예측 성능을 한층 끌어올릴 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기