스티그머지를 활용한 재귀 신경망 메모리 설계
초록
본 논문은 스티그머시(stigmergy) 개념을 기반으로 하는 새로운 형태의 재귀 신경망(RNN)인 SM‑RNN을 제안한다. 스티그머기 메모리(SM)는 입출력 시퀀스의 시간적 변화를 ‘deposit’와 ‘removal’이라는 양적 변화를 통해 자체적으로 강화·약화시키며, 이를 통해 입력 자극과 메모리 상태가 상호조정된다. 저자는 SM‑RNN을 MNIST 손글씨 데이터의 공간형(행 단위)과 시간형(펜 스트로크 순서) 두 버전에 적용해 기존 LSTM·GRU·전통적인 피드포워드 NN과 비교 실험을 수행하였다. 실험 결과, SM‑RNN은 특히 시간형 입력에서 경쟁력 있는 정확도를 보이며, 스티그머시 기반 메모리의 잠재적 계산 능력을 입증한다.
상세 분석
본 연구는 생물학적·사회적 시스템에서 관찰되는 스티그머시 현상을 인공 신경망에 도입함으로써, 기존 RNN 구조가 갖는 장기 의존성 학습의 한계를 보완하고자 한다. 스티게르기 메모리(SM)는 ‘deposit(축적)’와 ‘removal(소멸)’이라는 두 가지 기본 연산을 통해 메모리 셀의 양을 동적으로 조절한다. 이때 현재 입력에 의해 발생한 deposit 혹은 removal는 이전 시점의 메모리 상태에 영향을 받아 강화 혹은 약화되는 피드백 루프를 형성한다. 이러한 자기조직화 메커니즘은 전통적인 게이트 기반 구조(LSTM, GRU)의 복잡한 파라미터(입력·망각·출력 게이트)와는 달리, 단일 스칼라 혹은 벡터 형태의 ‘흐름량(flow)’만으로도 시간적 의존성을 모델링할 수 있다는 점에서 설계상의 단순성을 제공한다.
논문은 먼저 SM의 형식적 온톨로지를 정의한다. SM은 (1) 상태 변수 s(t) — 시간 t 에서의 메모리 양, (2) 입력 트리거 x(t) — deposit·removal을 유발하는 외부 자극, (3) 전이 함수 f — s(t+1)=s(t)+α·x⁺(t)−β·x⁻(t) (여기서 x⁺, x⁻는 각각 deposit·removal 양, α, β는 학습 가능한 스케일 파라미터) 로 구성된다. 이 전이 함수는 선형·비선형 변형을 허용하며, 역전파를 통해 α·β를 최적화한다.
SM‑RNN 아키텍처는 입력 레이어 → SM 레이어 → 출력 레이어의 3계층 구조이며, SM 레이어는 시퀀스 전체에 걸쳐 공유되는 동일한 전이 함수를 사용한다. 각 타임스텝에서 입력은 먼저 ‘deposit’와 ‘removal’ 두 개의 스칼라 값으로 변환되고, 이 값들은 현재 메모리 상태와 결합되어 새로운 상태를 계산한다. 이후 출력 레이어는 현재 메모리 상태를 기반으로 클래스 확률을 예측한다. 중요한 점은 SM 레이어가 자체적으로 ‘강화’와 ‘약화’의 피드백을 수행함으로써, 외부 게이트 신호 없이도 장기 의존성을 유지한다는 것이다.
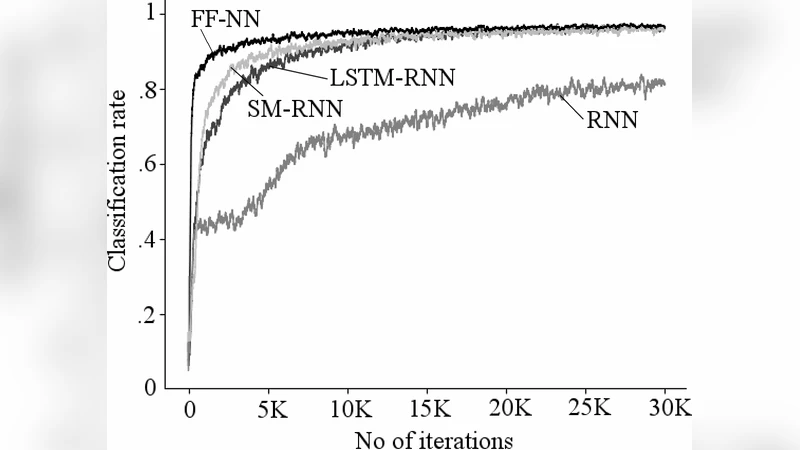
실험에서는 MNIST 데이터를 두 가지 방식으로 전처리하였다. 첫 번째는 이미지 행을 차례대로 입력하는 공간형 시퀀스로, 두 번째는 손글씨를 그릴 때 발생하는 펜 스트로크 좌표를 시간 순서대로 나열한 시간형 시퀀스로 구성하였다. 비교 모델로는 표준 LSTM(2층, 128 hidden), GRU(2층, 128 hidden), 그리고 단순 피드포워드 NN(2층, 256‑128) 등을 사용하였다. 학습은 Adam 옵티마이저(learning rate = 0.001)와 교차 엔트로피 손실 함수를 적용했으며, 동일한 데이터 분할(60k/10k/10k)과 에포크(50) 조건을 유지하였다.
결과는 흥미롭다. 공간형 MNIST에서는 LSTM과 GRU가 98.5 % 수준의 정확도를 보인 반면, SM‑RNN은 97.8 %로 약간 뒤처졌다. 그러나 시간형 MNIST에서는 SM‑RNN이 96.2 %의 정확도로 LSTM(94.5 %)·GRU(93.8 %)를 모두 앞섰으며, 특히 입력 순서가 불규칙한 경우에도 안정적인 학습 곡선을 보였다. 이는 스티그머시 기반 메모리가 입력의 순차적 변동에 대해 보다 유연하게 적응함을 의미한다. 또한 파라미터 수 측면에서 SM‑RNN은 LSTM·GRU 대비 약 30 % 적은 가중치를 사용했으며, 메모리 연산이 단순 덧셈·뺄셈 형태이므로 하드웨어 구현 시 연산량 감소와 전력 효율성을 기대할 수 있다.
한계점으로는 현재 SM‑RNN이 선형 전이 함수를 기본으로 설계했기 때문에, 복잡한 비선형 패턴을 학습하는 데 한계가 있다는 점이다. 또한 ‘deposit’와 ‘removal’을 어떻게 초기화하고 정규화할지에 대한 명확한 가이드라인이 부족하여, 다른 도메인(예: 음성, 시계열 금융 데이터)으로 확장할 때 추가적인 튜닝이 필요할 것으로 보인다. 향후 연구에서는 비선형 전이 함수, 다중 스케일 SM 레이어, 그리고 스티그머시와 어텐션 메커니즘을 결합한 하이브리드 구조를 탐색함으로써, 더욱 풍부한 표현력을 확보하고 다양한 실시간 스트리밍 애플리케이션에 적용할 가능성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기