빅데이터 시스템 저장소 솔루션 연구와 비교
초록
본 논문은 빅데이터 시스템에서 저장소 선택 시 고려해야 할 데이터 모델(문서, 키‑값, 그래프, 와이드 컬럼)과 80여 개 NoSQL 솔루션의 특성을 정성적으로 분석한다. 또한 Hadoop 기반 빅데이터 처리에 사용되는 파일 포맷을 비교하고, 탈중앙화 저장소와 블록체인의 향후 가능성을 논의한다.
상세 분석
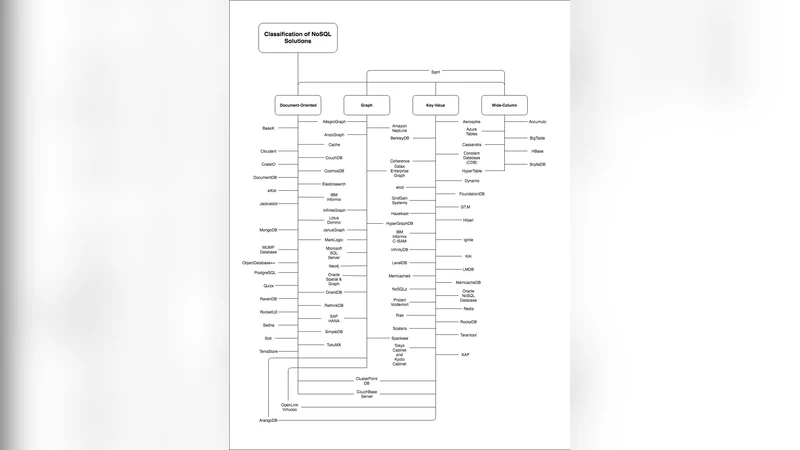
논문은 먼저 빅데이터 애플리케이션이 갖는 데이터 특성(볼륨, 다양성, 속도, 관계성 등)을 기준으로 네 가지 주요 NoSQL 데이터 모델을 구분한다. 문서형 데이터베이스는 반정형 JSON/XML 형태의 데이터를 자유롭게 저장·조회할 수 있어 스키마 변화가 빈번한 웹 로그, 사용자 프로필 등에 적합하다. 키‑값 스토어는 단순 조회와 초고속 쓰기가 요구되는 캐시, 세션 관리, IoT 센서 데이터에 강점을 보이며, 일관성 모델을 선택적으로 적용할 수 있다. 그래프 데이터베이스는 정점·간선 관계가 복잡한 소셜 네트워크, 사기 탐지, 추천 시스템 등에 최적화돼, 트래버설 연산을 효율적으로 수행한다. 와이드 컬럼 스토어는 대규모 시계열 데이터와 대용량 배치 처리에 유리하며, 컬럼 패밀리를 활용한 압축·인덱싱으로 읽기·쓰기 성능을 균형 있게 제공한다.
80개의 NoSQL 솔루션을 평가할 때 저자는 배포 방식(싱글·클러스터·멀티‑데이터센터), 일관성 보장(강일관성·최종일관성), 트랜잭션 지원, 확장성, 운영 복잡도, 커뮤니티·기업 지원 등 12가지 기준을 제시한다. 예를 들어, MongoDB는 풍부한 쿼리 언어와 자동 샤딩을 제공하지만, 복잡한 다중 문서 트랜잭션에서는 성능 저하가 발생한다. Cassandra는 라이트 최적화와 무중단 확장을 제공하지만, 읽기 지연이 상대적으로 높고 스키마 관리가 까다롭다. Neo4j는 그래프 탐색에 특화돼 빠른 응답성을 보이지만, 대규모 클러스터링이 제한적이다. 이러한 비교를 통해 개발자는 애플리케이션 요구사항과 운영 환경에 맞는 스토리지 엔진을 선택할 수 있다.
다음으로 논문은 Hadoop 에코시스템에서 사용되는 파일 포맷을 분석한다. 전통적인 Text/CSV는 인간 가독성이 높지만 압축 효율과 스키마 관리가 부족하다. SequenceFile은 키‑값 쌍을 바이너리 형태로 저장해 MapReduce와의 호환성이 좋지만, 컬럼 기반 접근에 한계가 있다. Avro는 스키마를 파일에 내장하고 빠른 직렬화를 제공하지만, 컬럼 프루닝을 지원하지 않는다. Parquet과 ORC는 컬럼 지향 포맷으로 압축률과 쿼리 성능이 뛰어나며, 특히 분석 워크로드에서 우수한 I/O 효율을 보인다. 다만, 쓰기 시 복잡한 인코딩 과정이 필요해 실시간 스트리밍에는 부적합할 수 있다.
마지막으로 탈중앙화 스토리지와 블록체인 기술을 차세대 빅데이터 저장소로 조망한다. IPFS, Filecoin 같은 분산 파일 시스템은 데이터 무결성과 영구성을 보장하면서 비용 효율적인 스토리지를 제공한다. 블록체인은 변조 방지와 투명한 데이터 기록을 가능하게 하지만, 트랜잭션 처리량과 저장 비용이 현재 수준에서는 대규모 데이터에 적용하기 어렵다. 논문은 이러한 신기술이 기존 NoSQL·Hadoop 스택과 어떻게 통합될 수 있는지, 그리고 보안·프라이버시·규제 측면에서의 과제들을 제시한다. 전체적으로 본 연구는 빅데이터 저장소 선택 시 고려해야 할 다차원적 요소들을 체계적으로 정리하고, 실무자에게 실질적인 의사결정 가이드를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기