조건부 적대적 네트워크를 이용한 장면 흐름 추정
본 논문은 스테레오 이미지 쌍으로부터 광학 흐름과 시차를 동시에 예측하는 장면 흐름(Scene Flow) 추정 모델인 SceneFlowGAN을 제안한다. 조건부 생성적 적대 신경망 구조를 채택해, 기존의 깊이 기반 방법보다 빠른 추론을 목표로 하며, Wasserstein GAN 손실과 평균 종단점 오류(EPE) 및 L1 시차 손실을 결합한 공동 손실 함수를 사용한다. 모델은 공개된 FlyingThings3D 데이터셋(최종 패스)으로 학습했으며,…
저자: Ravi Kumar Thakur, Snehasis Mukherjee
본 논문은 로봇 비전 분야에서 실시간으로 3차원 움직임을 포착할 수 있는 장면 흐름(Scene Flow) 추정의 필요성을 강조한다. 전통적인 방법은 광학 흐름과 시차를 별도로 계산한 뒤 3D 움직임을 재구성하는 방식으로, 밝기·그라디언트 불변성 가정이 깨지면 성능이 급격히 저하되고 연산 비용이 수분에서 수십 분에 이른다. 이러한 문제점을 해결하고자 저자들은 조건부 적대적 네트워크(Conditional GAN) 기반 모델인 SceneFlowGAN을 설계하였다.
**문제 정의 및 입력/출력**
입력은 두 시점(t, t+1)에서 촬영된 좌·우 스테레오 이미지 쌍 I = (I_t^L, I_{t+1}^L, I_t^R, I_{t+1}^R)이며, 목표는 4차원 장면 흐름 S = (u, v, d_t, d_{t+1})를 출력하는 것이다. 여기서 (u, v)는 광학 흐름, d_t와 d_{t+1}는 각각 시점 t와 t+1의 시차이다.
**아키텍처**
- **생성기(G)**: 기존 연구에서 제안된 SceneEDNet을 기반으로 하되, 인코더‑디코더 구조 사이에 동일 차원의 스킵 연결을 삽입해 저해상도에서 고해상도로 복원할 때 손실되는 공간 정보를 보존한다. 또한 모든 합성곱 층 뒤에 배치 정규화와 LeakyReLU를 적용해 학습 안정성을 강화하였다. 출력은 4채널 텐서(광학 흐름 2채널 + 시차 2채널)이다.
- **판별기(D)**: 조건부가 아닌 전통적인 형태로 설계되었으며, 3개의 합성곱‑배치정규화‑LeakyReLU 블록 뒤에 전결합층을 두어 최종적으로 “실제” 혹은 “생성” 여부를 0~1 확률값으로 반환한다. 판별기에는 0.4의 드롭아웃을 적용해 과적합을 방지한다.
**손실 함수**
- **GAN 손실(L_GAN)**: Wasserstein GAN(또는 Earth‑Mover’s Distance) 기반으로, 판별기가 실제와 생성된 장면 흐름을 구분하도록 학습한다. 이는 전통적인 교차 엔트로피 손실보다 기울기 소실 문제를 완화한다.
- **공동 손실(L_JointLoss)**: 두 부분으로 구성된다. (1) 광학 흐름에 대해 평균 종단점 오류(EPE)를 제곱합 형태로 계산하고, (2) 시차에 대해서는 L1 손실을 적용한다. 수식 (2)에서 보듯, 각 성분별 차이를 직접 최소화함으로써 생성기가 장면 흐름의 물리적 의미를 보존하도록 유도한다.
전체 목표 함수는 `min_G max_D (L_GAN + L_JointLoss)`이며, 학습 과정에서 판별기는 고정된 생성기 파라미터에 대해 최적화하고, 생성기는 판별기의 파라미터를 고정한 채 두 손실을 동시에 최소화한다.
**학습 및 데이터**
학습에는 FlyingThings3D 데이터셋의 ‘final pass’ 이미지(모션 블러·조명 변형 포함)를 사용하였다. 데이터는 3개의 서브셋(FlyingThings3D, Monkaa, Driving)으로 구성되며, 저자는 특히 FlyingThings3D의 세 가지 변형(A, B, C) 중 A와 C를 선택해 실험하였다. Adam 옵티마이저(learning rate = 1e‑5)와 1080 GPU에서 배치 크기와 epoch 수를 조절해 모델을 학습하였다.
**실험 결과**
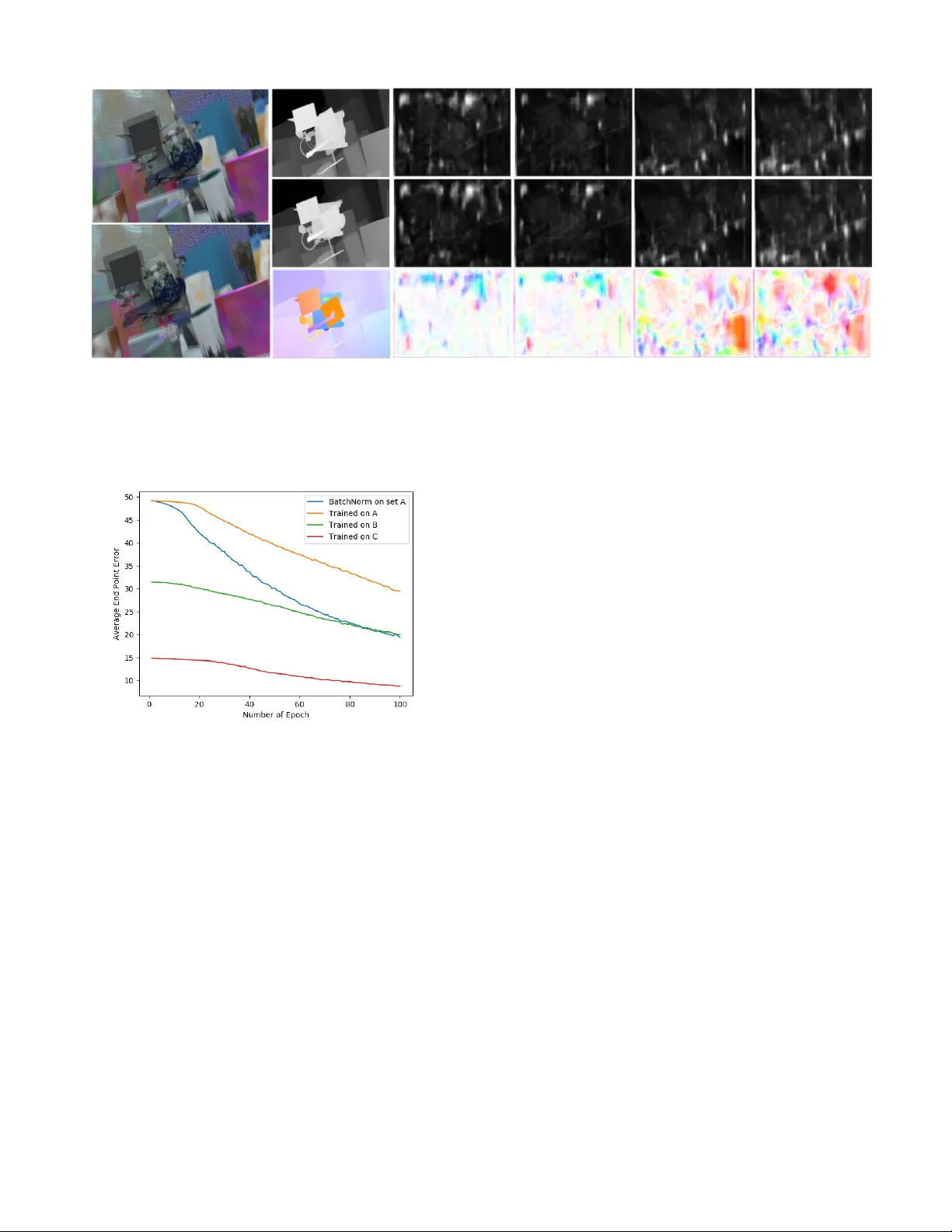
- **정성적 시각화**: Figure 4에서는 입력 스테레오 이미지와 Ground Truth, 그리고 모델이 예측한 광학 흐름·시차를 비교한다. 두 서브셋(A, C)에서 각각 70 epoch와 50 epoch 학습된 모델을 보여주며, epoch가 많을수록 경계와 움직임이 더 정확히 복원되는 경향을 확인한다.
- **Ablation Study**: 배치 정규화를 도입했을 때 SceneEDNet의 훈련 손실이 감소함을 Figure 5에서 확인한다. 또한 서로 다른 데이터 서브셋에 대한 학습 결과를 비교해, 데이터 분포가 모델 수렴 속도와 최종 손실에 미치는 영향을 분석한다.
- **정량적 평가**: 논문 본문에 구체적인 EPE, D1, 혹은 3D End‑Point‑Error와 같은 수치는 제시되지 않았으며, 테스트 세트에 대한 평균 오류 그래프만 간단히 언급한다.
**논문의 기여와 한계**
- **기여**: (1) 장면 흐름 추정에 GAN을 최초 적용, (2) 광학 흐름과 시차를 공동 손실로 동시에 학습, (3) 기존 SceneEDNet에 배치 정규화와 스킵 연결을 도입해 학습 안정성 및 성능 향상.
- **한계**: (가) 합성 데이터에만 의존해 실제 환경에서의 일반화가 검증되지 않음, (나) 판별기가 조건부가 아니므로 입력 이미지와의 직접적인 연관성을 학습하지 못함, (다) 정량적 비교가 부족해 기존 최첨단 방법과의 상대적 우위를 판단하기 어려움, (라) 4D 출력 구조가 메모리·연산 요구가 높아 실시간 로봇 시스템에 바로 적용하기엔 부담이 있다.
**향후 연구 방향**
저자는 자연 장면을 위한 대규모 데이터셋을 생성하고, 조건부 판별기와 멀티스케일 피처 융합을 도입해 정밀도를 높이는 방안을 제시한다. 또한, 실제 로봇 플랫폼에서의 실시간 추론을 목표로 경량화 모델 설계와 하드웨어 가속(예: TensorRT, FPGA) 적용도 고려할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기