잠재클래스 모델 기반 화자 다이어리제이션의 새로운 패러다임
초록
본 논문은 기존의 생성 모델 중심 변분 베이즈(VB) 방식과 달리, 잠재클래스 모델(LCM)을 활용해 화자 다이어리제이션을 수행한다. i‑vector, PLDA, SVM 등 판별적 모델을 결합한 LCM‑Ivec‑PLDA, LCM‑Ivec‑SVM, LCM‑Ivec‑Hybrid 시스템을 제안하고, 이웃 윈도우, HMM 스무딩, 계층적 군집 초기화라는 세 가지 보강 기법을 도입한다. NIST RT‑09 SDM, CALLHOME, SRE08 실험에서 DER을 크게 낮추어 VB 대비 각각 23.5 %, 27.1 %, 43.0 %의 상대 개선을 달성하였다.
상세 분석
논문은 화자 다이어리제이션을 “누가 언제 말했는가”를 판별하는 문제로 정의하고, 기존의 두 가지 접근법—하향식(분할‑군집)과 상향식(계층적 군집)—의 한계점을 짚는다. 특히 변분 베이즈(VB) 방법은 짧은 고정 길이 세그먼트를 사용해 소프트 클러스터링을 제공하지만, (1) 단일 목적 함수(전체 가능도 최대화) 기반의 생성 모델에 국한되어 화자 구분 능력이 제한되고, (2) 세그먼트가 짧아 각 세그먼트‑화자 결합 확률이 부정확해 성능 저하가 발생한다. 또한 초기 prior에 민감해 한 화자가 지배적인 경우 불균형 오류가 발생한다.
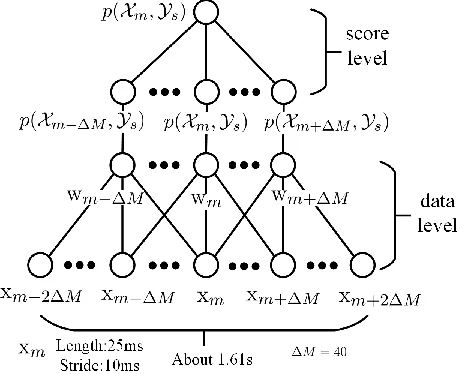
이를 극복하기 위해 저자들은 잠재클래스 모델(LCM)을 도입한다. LCM은 관측 세그먼트 Xₘ와 잠재 화자 클래스 Yₛ, 그리고 이진 지시 변수 iₘₛ를 결합한 공동 확률 p(Xₘ, Yₛ, iₘₛ)를 정의한다. 목표는 로그 가능도 log p(X, Y, I)를 최대화하면서 S개의 클래스 제약을 유지하는 것이며, 이를 세 단계의 변분 근사(식 3‑6)로 분해한다. 첫 단계에서는 현재 추정된 p(Xₘ, Yₛ)를 이용해 후방 확률 qₘₛ = p(iₘₛ|Xₘ, Yₛ) 를 업데이트하고, 두 번째 단계에서는 qₘₛ를 prior 로 삼아 Yₛ(화자 표현)를 재추정한다. 세 번째 단계는 Yₛ와 qₘₛ를 이용해 p(Xₘ, Yₛ|iₘₛ)를 계산, 다시 첫 단계로 순환한다. 이 순환은 VB의 E‑M 구조와 유사하지만, LCM은 p(Xₘ, Yₛ) 를 판별적 모델(PLDA, SVM)로 직접 추정할 수 있게 해준다.
구현 측면에서 저자들은 세 가지 LCM 변형을 제시한다. LCM‑Ivec‑PLDA는 i‑vector와 PLDA 스코어를 p(Xₘ, Yₛ) 로 사용하고, LCM‑Ivec‑SVM은 선형 SVM 결정 함수를 활용한다. Hybrid 버전은 PLDA와 SVM 점수를 가중 평균해 두 모델의 장점을 결합한다. 또한, (1) 이웃 윈도우 기법을 도입해 각 세그먼트의 주변 정보를 Xₘ에 포함시켜 단일 세그먼트의 불확실성을 감소시켰으며, (2) HMM을 적용해 연속적인 화자 전환을 부드럽게 제어하고, (3) 초기 민감도를 완화하기 위해 계층적 군집(AHC) 결과를 hard/soft prior 로 사용해 초기값을 제공한다.
실험은 NIST RT‑09 스피커 다이어리제이션 데이터베이스의 단일 원거리 마이크(SDM) 조건을 주요 평가 환경으로 삼았다. 기본 시스템(VB) 대비 LCM‑Ivec‑PLDA, LCM‑Ivec‑SVM, LCM‑Ivec‑Hybrid은 각각 DER에서 23.5 %, 27.1 %, 43.0 %의 상대 개선을 보였으며, CALLHOME97, CALLHOME00, SRE08 short2‑summed 조건에서도 Hybrid 모델이 최고 성능을 기록했다. 결과는 LCM이 생성 모델에 얽매이지 않고 판별적 정보를 효과적으로 통합함으로써 짧은 세그먼트에서도 강인한 화자 구분을 가능하게 함을 입증한다.
이 논문은 (1) LCM이라는 통계적 프레임워크가 VB와 동일한 소프트 클러스터링 장점을 유지하면서도 판별 모델을 자유롭게 삽입할 수 있음을, (2) 초기화와 시간적 연속성을 보강하는 실용적 기법들이 전체 시스템 안정성을 크게 향상시킴을, (3) 실험을 통해 제안된 LCM‑Hybrid이 현재 가장 널리 사용되는 다이어리제이션 파이프라인을 능가한다는 점을 강조한다. 향후 연구에서는 다중 마이크(MDM) 환경, 비정형 언어·노이즈 조건, 그리고 end‑to‑end 딥러닝 기반 특징 추출과의 결합을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기