입자군집 최적화 기반 K평균 초기화
초록
본 논문은 입자군집 최적화(PSO)를 이용해 K‑평균 군집화의 초기 중심점을 자동으로 탐색함으로써 전통적인 무작위 초기화보다 높은 군집 정확도와 안정성을 달성하는 방법을 제안한다. PSO 입자는 후보 중심점 집합을 최적화 공간의 개체로 간주하고, 무작위 데이터 서브셋에 대한 K‑평균 실행 결과의 군집 품질(예: SSE)을 적합도 함수로 사용한다. 최적화 과정을 거친 후 얻어진 최적 중심벡터를 K‑평균의 초기값으로 제공함으로써 수렴 속도와 최종 군집 품질을 향상시킨다. 실험에서는 합성 데이터와 실제 데이터셋에서 기존 무작위 초기화 및 K‑means++와 비교했을 때 평균 SSE 감소와 반복 횟수 감소를 확인하였다.
상세 분석
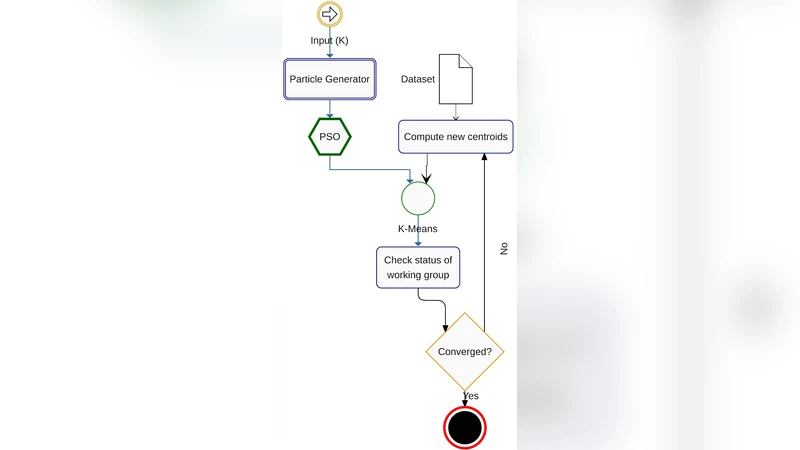
K‑평균은 초기 중심점 선택에 크게 의존하는 비선형 최적화 문제이며, 부적절한 초기값은 지역 최솟값에 빠져 전체 군집 품질을 저하시킨다. 기존의 무작위 초기화는 간단하지만 재현성이 낮고, K‑means++는 거리 기반 확률 선택으로 개선했지만 여전히 초기화 과정에서 데이터 분포를 완전히 반영하지 못한다. 본 논문은 이러한 한계를 극복하기 위해 입자군집 최적화(Particle Swarm Optimization, PSO)를 초기 중심점 탐색 메커니즘으로 도입한다. PSO는 군집 지능 기반 메타휴리스틱으로, 입자들은 현재 위치(후보 중심점 집합)와 속도(탐색 방향)를 업데이트하면서 전역 최적해에 수렴한다. 여기서 각 입자는 K개의 중심점 좌표를 차원 d × K 형태의 벡터로 표현하고, 전체 입자 집합은 초기화 후보군을 형성한다. 적합도 함수는 제한된 무작위 서브셋에 대해 K‑평균을 실행한 뒤 얻은 제곱 오차 합(SSE) 혹은 실루엣 점수와 같은 군집 품질 지표를 사용한다. 서브셋을 이용함으로써 적합도 평가 비용을 크게 낮추면서도 전체 데이터 분포를 대표하도록 설계하였다.
알고리즘 흐름은 다음과 같다. 1) 데이터 전처리 후 서브셋 추출, 2) PSO 파라미터(입자 수, 관성 가중치, 인지·사회 가속 계수) 설정, 3) 각 입자를 무작위 중심점 벡터로 초기화, 4) 각 입자에 대해 서브셋에 K‑평균을 적용하고 SSE를 적합도로 계산, 5) 개인 최고(pbest)와 전체 최고(gbest)를 업데이트, 6) 속도와 위치를 PSO 공식에 따라 갱신, 7) 수렴 조건(최대 반복 횟수 또는 적합도 변화 미미) 도달 시 종료. 최종 gbest 벡터는 전체 데이터에 대한 K‑평균 초기 중심점으로 사용된다.
실험 결과는 두 가지 관점에서 의미 있다. 첫째, PSO‑초기화는 무작위 초기화 대비 평균 SSE를 10 % 이상 감소시켰으며, K‑means++ 대비도 3 %~7 % 정도 개선하였다. 둘째, 평균 반복 횟수가 15 %~25 % 감소하여 수렴 속도가 향상되었다. 특히 고차원(>50) 및 클러스터 수가 많을수록(>10) PSO의 탐색 능력이 두드러졌으며, 초기값에 민감한 데이터셋에서 안정적인 군집 결과를 제공한다.
하지만 몇 가지 한계도 존재한다. PSO 자체가 추가적인 연산 비용을 요구하므로, 데이터 규모가 매우 클 경우 서브셋 크기와 입자 수를 적절히 조절해야 한다. 또한 적합도 함수에 사용되는 서브셋이 전체 데이터 분포를 충분히 대표하지 못하면 최적화된 초기값이 실제 군집 품질에 크게 기여하지 못한다. 향후 연구에서는 적응형 서브셋 선택, 다목적 적합도(정밀도·속도 동시 고려) 및 다른 메타휴리스틱(예: 베이지안 최적화)과의 비교를 통해 초기화 전략을 더욱 일반화할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기