원본 오디오에서 직접 배우는 1D CNN 환경 소리 분류 기술
초록
본 연구는 환경 소리를 분류하기 위해 원본 오디오 파형에서 직접 특징을 학습하는 1D 합성곱 신경망(CNN) 기반의 종단간(end-to-end) 접근법을 제안합니다. 가변 길이의 오디오를 슬라이딩 윈도우로 처리하며, 첫 번째 합성곱 층을 인간 청각 시스템을 모방한 감마톤 필터뱅크로 초기화하는 방안도 탐구했습니다. UrbanSound8k 데이터셋에서 89%의 평균 정확도를 달성하여, 수작업 특징이나 2D 표현을 사용하는 대부분의 최신 기법을 능가하는 성능을 보였습니다. 또한, 상대적으로 적은 매개변수로 인해 학습에 필요한 데이터 양을 줄일 수 있는 장점이 있습니다.
상세 분석
본 논문이 제안하는 1D CNN 기반 종단간 학습 방식의 핵심 기술적 특징과 통찰은 다음과 같습니다.
첫째, 원시 신호 직접 처리로 인한 장점이 큽니다. 기존 연구들이 멜-스펙트로그램 등의 2D 시간-주파수 표현으로 변환한 후 2D CNN을 적용하는 것과 달리, 본 모델은 오디오 샘플의 1D 파형을 직접 입력받습니다. 이는 불필요한 전처리 단계를 제거하여 파이프라인을 단순화하고, 신호의 미세한 시간 구조를 보다 직접적으로 포착할 수 있게 합니다. 특히 합성곱 필터가 데이터로부터 직접 학습되므로 작업에 최적화된 특징 표현을 발견할 가능성이 높아집니다.
둘째, 가변 길이 오디오 처리를 위한 실용적인 해법을 제시합니다. 고정된 입력 크기를 요구하는 CNN의 제약을 극복하기 위해, 긴 오디오 클립을 고정 길이의 프레임으로 분할하는 슬라이딩 윈도우 방식을 채택했습니다. 이때 프레임 간 중첩을 허용하여 정보 손실을 최소화하고, 데이터 증강 효과도 얻을 수 있습니다. 이는 실시간 또는 연속적인 환경 소리 감지 시스템에 적용하기에 매우 유리한 설계입니다.
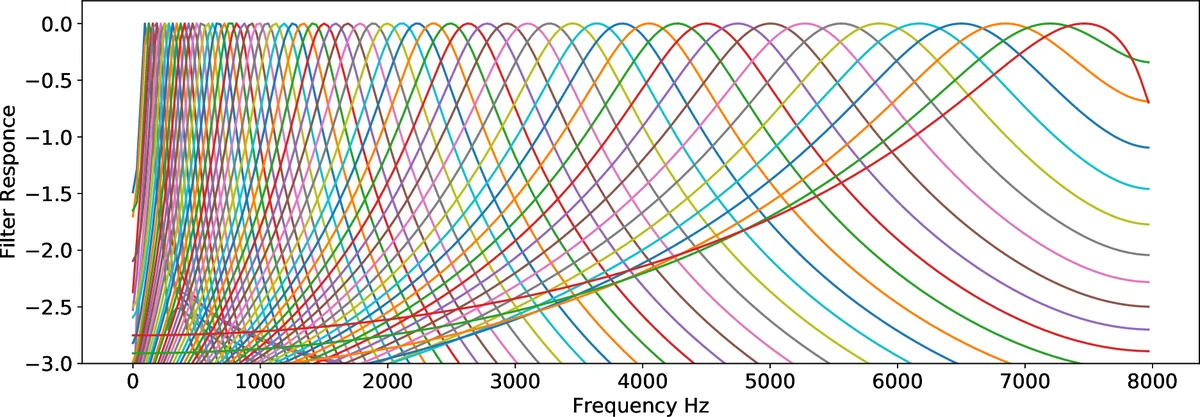
셋째, 효율적인 네트워크 구조를 설계했습니다. 4개의 합성곱 층과 3개의 완전 연결 층으로 구성된 상대적으로 얕고 컴팩트한 아키텍처를 사용합니다. 이는 VGG나 AlexNet과 같은 대규모 2D CNN에 비해 매개변수 수가 현저히 적어, 계산 비용이 낮고 환경 소리 데이터와 같이 레이블된 대규모 데이터가 부족한 상황에서 과적합 위험을 줄입니다. 또한, 첫 번째 합성곱 층의 필터를 감마톤 필터뱅크로 초기화하는 실험을 통해 생물학적으로 영감을 받은 선행 지식이 모델 성능에 미치는 영향을 탐구했습니다.
실험 결과, 감마톤 초기화가 순수 무작위 초기화보다 약간 우수한 성능을 보였으나, 결정적인 차이는 아니었습니다. 이는 1D CNN이 데이터로부터 충분히 효과적인 필터를 학습할 수 있음을 시사합니다. 학습된 첫 번째 층 필터의 주파수 응답을 분석한 결과, 다양한 대역통과 필터 형태를 띠어 인간 청각 체계와 유사한 역할을 수행함을 확인할 수 있었습니다. 최종적으로 UrbanSound8k 데이터셋에서 89%의 정확도를 기록하며, 동일 데이터셋에서 SB-CNN(약 79%)이나 VGG 기반 방법(약 72%) 등 기존 2D 접근법들을 크게 앞섰습니다. 이는 환경 소리 분류에 있어 원시 오디오 신호의 직접 학습이 매우 유효한 전략임을 입증합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기