뉴스로 보는 국제 관계 흐름 추적
초록
본 논문은 뉴스 기사에서 추출한 동사와 명사를 활용해 국가 간 관계를 무감독 신경망으로 모델링한다. 기존 관계 모델링 네트워크(RMN)를 개선한 LARN(Linguistically Aware Relationship Network)은 얕은 언어 정보를 통합해 관계 묘사를 더 의미 있게 만들고, 새롭게 제안한 키 이벤트 정렬 평가 지표와 현장 인간 평가를 통해 성능을 검증한다. 실험 결과 LARN이 관계 서술어와 시간적 추세를 더 정확히 포착함을 보여준다.
상세 분석
이 연구는 국제 관계를 이해하기 위해 ‘관계 추적’이라는 새로운 과제에 접근한다. 기존의 감독식 관계 추출은 사전 정의된 관계 유형에 한정돼 급변하는 국제 정세를 포착하기 어렵다. 이에 저자들은 무감독 신경망 기반의 관계 모델링 네트워크(RMN)를 출발점으로 삼아, 두 가지 핵심적인 언어적 힌트를 모델에 주입한다. 첫째, 동사(predicate)는 국가 간 상호작용을 직접 기술하는 핵심 어휘로 간주하고, 문장 내에서 주어·목적어가 모두 존재하는 경우에만 선택한다. 둘째, 명사와 고유명사는 관계의 배경(context)을 제공한다는 가정 하에, 어텐션 메커니즘을 통해 각 국가 쌍마다 가중치를 부여한다. 이렇게 함으로써 ‘동사만’을 사용했을 때 발생할 수 있는 의미 손실을 보완한다.
모델 구조는 크게 세 단계로 구성된다. (1) 입력 문장에서 추출한 동사와 명사를 각각 GloVe 임베딩으로 변환한다. (2) 동사 집합을 단순히 평균하는 것이 아니라, 드롭아웃을 적용해 일부 동사를 무작위로 제외함으로써 모델이 특정 어휘에 과도하게 의존하는 것을 방지한다. (3) 명사 임베딩에 시간 정보를 원-핫 형태로 결합하고, 이를 tanh와 선형 변환을 거쳐 어텐션 스코어를 계산한다. 어텐션 스코어는 해당 국가 쌍의 쿼리 임베딩과 내적해 구해지며, 이를 통해 명사 가중합을 얻는다. 마지막으로 동사, 국가 쌍, 명사 세 벡터를 연결(concatenate)하고 ReLU와 Softmax를 거쳐 관계 임베딩에 대한 가중치 분포(d_a)를 산출한다. 이 가중치 분포와 사전 정의된 K개의 관계 임베딩 행렬(R)을 곱해 재구성 벡터(r_a)를 만든 뒤, 원본 동사 집합 벡터(v_label)와의 코사인 유사도를 최대화하는 마진 손실과 관계 임베딩의 정규성을 촉진하는 보조 손실을 동시에 최소화한다.
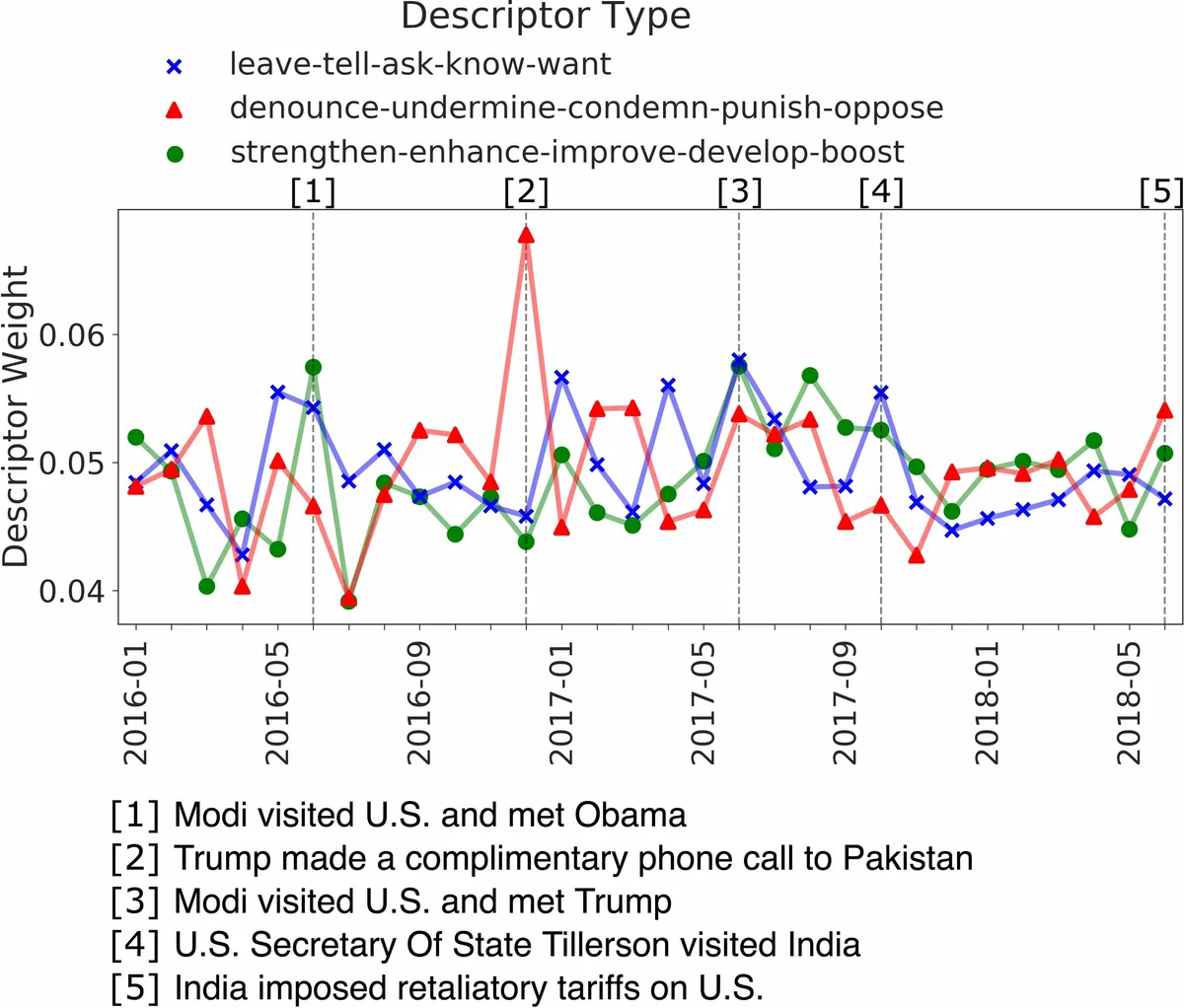
데이터 측면에서 저자들은 2016년~2018년 사이의 12개 국가(미국, 러시아, 중국 등) 쌍을 대상으로 NOW 코퍼스에서 1.2백만 문장을 추출했다. 각 국가별 별칭(alias)과 지도자 이름까지 포함해 평균 3.5개의 별칭을 정의함으로써 언급 탐지를 강화했다. 동사와 명사는 spaCy 의 의존 구문 분석 결과를 이용해 추출했으며, 평균적으로 국가 쌍당 21.6K개의 동사와 201K개의 명사가 확보되었다. 또한 8개의 가장 빈번한 국가 쌍에 대해 30개월 동안 약 5개의 핵심 사건을 수동으로 라벨링해, 모델이 생성한 시간적 관계 추세와 실제 사건 발생 시점을 정량적으로 정렬하는 새로운 평가 지표를 설계했다.
실험 결과는 두 가지 차원에서 LARN의 우수성을 입증한다. 첫째, 관계 서술어(top‑5) 분석에서 LARN이 ‘denounce’, ‘strengthen’, ‘negotiate’ 등 의미가 명확한 동사를 높은 가중치로 학습한 반면, RMN은 ‘seem’, ‘thing’ 등 내용이 흐린 토큰을 상위에 배치했다. 둘째, 시간적 추세 시각화에서 LARN은 미국‑중국 관계의 ‘strengthen’(무역 협상)과 ‘criticize’(무역 전쟁) 변화를 키 이벤트와 일치시키는 반면, RMN은 흐릿한 추세를 보여 인간 평가자들이 선호하지 않았다. 현장 사용자 연구에서는 75.9%가 LARN이 제공하는 관계 서술어를, 85.5%가 시간적 추세를 더 직관적이라고 평가했으며, 정치학·언어학 전공 학생들과 NLP 연구자 모두 모델의 해석 가능성과 지역별 차이 분석(예: 싱가포르 매체는 ‘strengthening’, ‘purchasing’에 초점)에서 긍정적인 피드백을 제공했다.
한계점으로는 (1) 관계 임베딩 수 K와 차원 d를 사전에 고정해야 하는 점, (2) 명사 어텐션이 여전히 잡음(irrelevant nouns)으로 인해 불필요한 가중치를 받을 가능성, (3) 시간적 연속성을 모델링하지 않아 급격한 관계 변화를 포착하는 데는 유리하지만, 장기적인 추세 분석에는 추가적인 시계열 모듈이 필요할 수 있다는 점을 들 수 있다. 향후 연구에서는 다중 언어 뉴스, 소셜 미디어 데이터와 결합해 보다 풍부한 국제 관계 맥락을 구축하고, 인간‑기계 협업 인터페이스를 설계해 사용자가 직접 키 이벤트를 삽입·조정할 수 있는 시스템을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기