전조 가속 지진성 텍스트 분류와 지진 예측 연구 흐름 분석
초록
본 연구는 1988년부터 2010년까지 발표된 100편의 전조 가속 지진성 논문을 대상으로 Naive Bayes, k‑NN, SVM, Random Forest 등 네 가지 지도학습 모델을 적용해 이진 및 다중 클래스 분류 성능을 평가한다. 라벨은 Mignan(2011)의 기준에 따라 ‘비임계 과정’, ‘중립’, ‘임계 과정 가정’, ‘임계 과정 입증’ 네 단계로 정의하였다. 작은 데이터셋 특성상 Naive Bayes가 86%의 교차 검증 정확도와 다중 클래스에서 최고 78% 정확도를 기록하며 가장 우수한 모델로 나타났다. 2011년 이후 새로 발표된 12편에 대한 테스트에서는 F1 점수가 60%에 그쳐 일반화 능력이 제한적임을 확인했다. 이는 저자 교체와 용어 변화가 라벨링 일관성을 해친 것으로 해석된다. 그러나 ‘비임계 과정’과 ‘임계 과정 입증’ 사이의 극단적 라벨 구분에서는 80% 이상의 F1 점수를 유지해 키워드 기반 Naive Bayes 접근이 여전히 유용함을 시사한다.
상세 분석
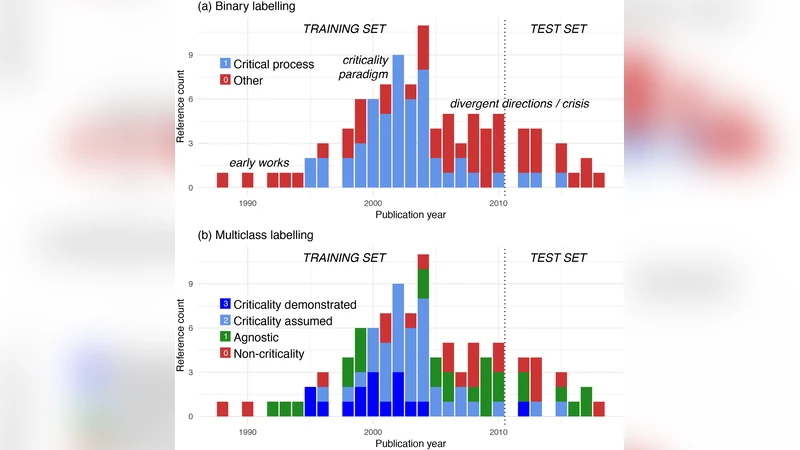
이 논문은 지진학 분야, 특히 전조 가속 지진성(precursory accelerating seismicity)이라는 좁은 연구 영역에 텍스트 마이닝과 기계학습을 최초로 적용한 시도라 할 수 있다. 연구자는 먼저 1988년부터 2010년까지 발표된 100편의 논문을 수집하고, Mignan(2011)의 라벨링 체계를 그대로 차용해 ‘비임계 과정(critical process not explained)’, ‘중립(agnostic)’, ‘임계 과정 가정(critical process assumed)’, ‘임계 과정 입증(critical process demonstrated)’ 네 가지 클래스로 구분하였다. 라벨링은 전문가가 직접 수행했으며, 이는 라벨링 편향 가능성을 내포하지만, 해당 분야의 전문성을 반영한다는 점에서 의미가 있다.
데이터 전처리 단계에서는 일반적인 텍스트 정제(불용어 제거, 어간 추출 등)와 TF‑IDF 벡터화가 이루어졌으며, 차원 축소 없이 전체 피처를 그대로 사용했다. 이는 작은 샘플 수(100개) 대비 피처 수가 많아 과적합 위험이 존재함을 의미한다. 따라서 모델 선택에 있어 ‘데이터가 작을 때 강건한 성능을 보이는’ Naive Bayes를 포함한 네 가지 알고리즘을 비교하였다.
성능 평가는 5‑fold 교차 검증을 통해 정확도, 정밀도, 재현율, F1 점수를 종합적으로 보고했으며, 이진 분류(임계 vs 비임계)에서는 Naive Bayes가 86% 정확도로 가장 우수했다. 이는 베이즈 정리 기반의 확률 모델이 작은 데이터셋에서 클래스 간 사전 확률과 단어 조건부 확률을 효과적으로 추정하기 때문으로 해석된다. 반면, k‑NN과 SVM은 피처 차원의 저주와 거리 기반 판단의 한계로 성능이 뒤처졌다. Random Forest는 앙상블 구조에도 불구하고 트리 수가 제한적이었고, 부트스트랩 샘플링이 충분히 다양하지 않아 과적합이 발생했다.
다중 클래스(4‑class) 상황에서는 최고 78% 정확도를 기록했으며, 특히 ‘비임계 과정’과 ‘임계 과정 입증’ 사이의 구분이 명확해 높은 정밀도와 재현율을 보였다. 그러나 ‘중립’과 ‘임계 과정 가정’ 라벨은 서로의 키워드가 겹치고, 논문의 어조가 모호하기 때문에 모델이 거의 무작위 수준(≈25%)의 성능을 나타냈다. 이는 라벨 자체가 주관적이며, 텍스트에 내재된 정보가 충분히 차별화되지 않음을 시사한다.
일반화 테스트로 2011년 이후 발표된 12편을 별도 검증 세트로 사용했을 때, 전체 F1 점수는 60%에 머물렀다. 저자 교체, 새로운 연구 트렌드, 그리고 용어 변화(예: ‘critical cascade’ 대신 ‘self‑organized criticality’)가 기존 라벨링과 어휘 빈도에 큰 차이를 만들었다. 이러한 도메인 드리프트는 작은 코퍼스 기반 모델이 최신 문헌에 적용될 때 흔히 겪는 문제이며, 지속적인 라벨 업데이트와 도메인 어휘 사전 관리가 필요함을 강조한다.
키워드 기반 Naive Bayes의 posterior probability 분석을 통해, ‘critical’, ‘cascade’, ‘foreshock’, ‘stress’ 등은 ‘임계 과정 입증’ 라벨에 높은 확률을 부여했으며, ‘loading’, ‘static’, ‘elastic’ 등은 ‘비임계 과정’ 라벨에 기여했다. 이러한 확률 분포는 도메인 전문가가 라벨링 기준을 재검토하거나, 새로운 라벨링 스키마를 설계할 때 투명한 근거를 제공한다.
결론적으로, 이 연구는 작은 규모의 전문 분야 텍스트 코퍼스에서도 Naive Bayes가 충분히 경쟁력 있는 성능을 보이며, 라벨링 체계와 도메인 어휘 관리가 모델 일반화에 핵심적인 영향을 미친다는 점을 실증한다. 향후 연구에서는 라벨링 자동화와 함께 사전 학습된 언어 모델(BERT, SciBERT 등)을 활용해 피처 표현을 강화하고, 도메인 적응 기법을 도입해 시계열적 용어 변화를 보정하는 방안을 모색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기