전자건강기록을 활용한 의료기기 사후감시 자동화
초록
본 연구는 약한 지도학습(weak supervision)과 딥러닝을 결합해 전자건강기록(EHR) 속 임상노트를 자동으로 분석하고, 고관절 인공관절 치환술 환자의 임플란트 종류, 합병증 및 통증 언급을 추출한다. 라벨링 함수 50개를 이용해 대규모 약한 라벨을 생성하고, 이를 기반으로 학습한 모델은 96.3% 정밀도, 98.5% 재현율, 97.4% F1 점수를 달성했으며, 기존 규칙 기반 방법보다 12.7~53.0% 높은 성능을 보였다. 추출된 사건을 구조화 데이터와 결합해 생존 분석을 수행한 결과, 임플란트 모델별 재수술 위험 및 통증 빈도에 유의한 차이가 있음을 확인하였다.
상세 분석
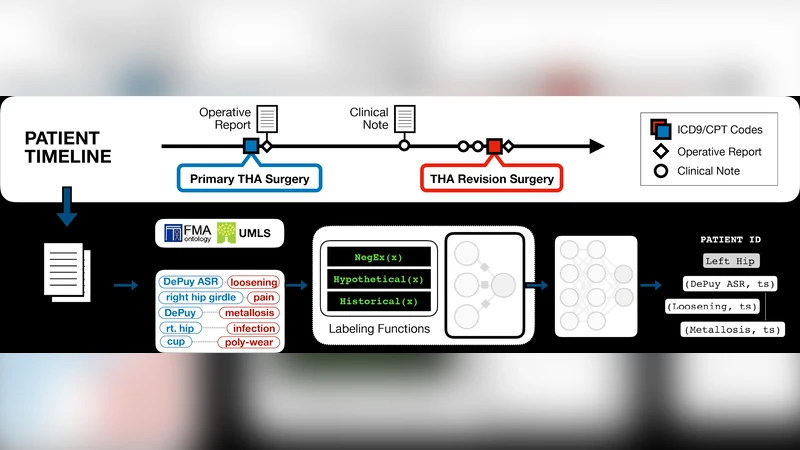
이 논문은 의료기기 사후감시 분야에서 가장 큰 장애물 중 하나인 라벨링 비용 문제를 약한 지도학습(framework Snorkel)으로 해결한다는 점에서 혁신적이다. 먼저 1.7백만 명의 환자 중 고관절 전치환술을 받은 6,583명을 코호트로 정의하고, ICD‑9 및 CPT 코드를 이용해 구조화된 수술·재수술 정보를 추출한다. 임상노트는 spaCy로 문장 단위로 토큰화하고, UMLS와 자체 사전을 결합한 규칙 기반 태거로 임플란트, 합병증, 해부학적 위치, 통증 엔터티를 식별한다. 여기서 핵심은 ‘라벨링 함수’를 통해 엔터티 쌍(예: 통증‑해부부위, 합병증‑임플란트)마다 긍정·부정·보류 라벨을 자동 생성한다는 점이다. 총 50개의 라벨링 함수(공통 17개, 통증‑해부부위 전용 7개, 합병증 전용 25개)는 문서 섹션, 부정·가정·과거 시제 등 임상 NLP에서 흔히 활용되는 프리미티브를 활용한다. 라벨링 함수들의 투표 행렬을 Snorkel의 생성 모델에 입력하면 각 후보 관계에 대한 확률 라벨이 추정되고, 이를 ‘약한 라벨’로 삼아 딥러닝 분류기(아마도 BERT 기반)를 학습한다. 이렇게 학습된 모델은 원본 텍스트만을 입력으로 받아 엔터티 간 관계를 예측하므로, 라벨링 함수가 포착하지 못한 복잡한 의미론적 패턴도 포괄한다.
성능 평가는 Stanford Total Joint Registry와 비교했으며, 임플란트 식별, 합병증·통증 사건 검출 모두에서 96% 이상의 정밀도와 98% 이상의 재현율을 기록했다. 특히 구조화된 코드만 사용할 때 대비 합병증 사건을 6배 이상 포착했으며, 이는 사후감시 신호 탐지의 민감도를 크게 높인다. 이후 추출된 사건 데이터를 Cox 비례위험 모델과 음이항 회귀, t‑검정 등에 투입해 임플란트 모델별 ‘합병증‑무 사건 생존율’을 추정했다. 결과는 특정 임플란트 모델이 재수술 위험이 유의하게 높거나 낮으며, 재수술 전 통증 언급 횟수가 평균 4.97회(재수술군) vs. 3.23회(비재수술군)로 차이가 났음을 보여준다. 이는 기존 코드 기반 감시가 놓칠 수 있는 미세한 임상 신호를 텍스트 기반 접근법이 보완한다는 강력한 증거다.
한계점으로는 라벨링 함수 설계에 전문가 시간 투입이 필요하고, 단일 기관 데이터에 국한돼 외부 일반화 검증이 부족하다는 점을 들 수 있다. 또한, 텍스트에서 부정·가정·과거 시제를 정확히 구분하는 NLP 전처리 단계가 오류를 일으킬 경우 downstream 모델 성능에 연쇄적 영향을 미칠 수 있다. 그럼에도 불구하고, 라벨링 함수와 딥러닝을 결합한 파이프라인은 라벨링 비용을 획기적으로 절감하면서도 높은 정확도를 유지하므로, 국가 차원의 의료기기 사후감시 체계에 적용 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기