스마트 스피커 음성 인터페이스의 재생 공격 취약성 분석 및 고차 스펙트럼 기반 방어 기법
초록
본 논문은 Amazon Echo와 Google Home 등 음성 기반 스마트 스피커가 재생(Replay) 공격에 취약함을 실험적으로 입증하고, 마이크‑스피커‑마이크(MSM) 체인에서 발생하는 고차 비선형 왜곡을 모델링한다. 고차 스펙트럼 분석(HOSA) 중 바이코히런스와 그 파라미터(QPC, Gaussianity, Linear‑ity 테스트)를 활용해 학습‑비의존적인 재생 공격 탐지 프레임워크를 제안한다. 실험 결과, 제안 기법은 원본 음성과 재생 음성 사이의 바이코히런스 크기·위상 차이를 효과적으로 포착하여 높은 탐지 정확도를 보인다.
상세 분석
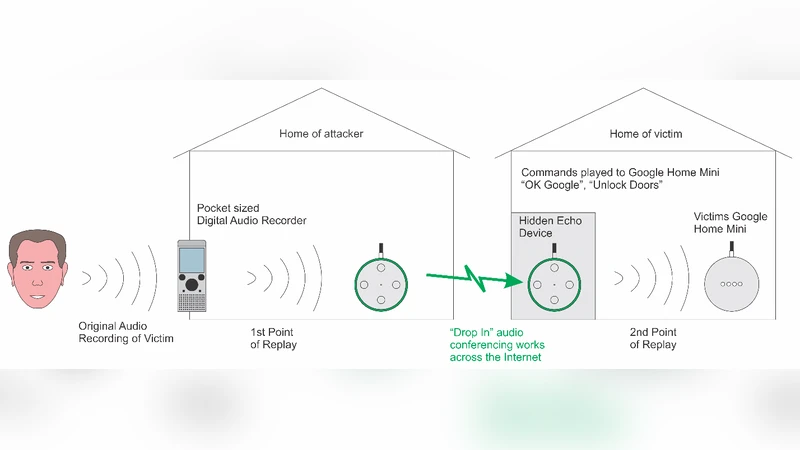
본 연구는 스마트 스피커의 자동 화자 인증(ASV) 시스템이 현재 구현된 형태에서는 ‘Wake‑Word’ 검증만 수행하고, 이후의 명령에 대해서는 화자 식별을 수행하지 않는 구조적 결함을 지적한다. Amazon Echo와 Google Home을 대상으로 수행한 세 차례 실험에서는, 사용자의 음성 명령을 사전에 녹음한 뒤 Drop‑In 기능을 이용해 원격으로 재생함으로써, 조명 제어, 문 잠금 해제, 구매 명령 등 실제 서비스에 영향을 미치는 공격이 성공함을 보여준다. 이러한 실험적 증거는 기존 ASV가 재생 공격에 대한 내성을 갖추지 못했으며, 특히 Google Home은 ‘OK Google’라는 웨이크워드만 검증하고 이후의 화자 차이를 무시한다는 점을 부각한다.
논문은 이러한 취약성을 이론적으로 설명하기 위해 마이크‑스피커‑마이크(MSM) 체인을 비선형 시스템으로 모델링한다. 재생 과정에서 마이크와 스피커 각각이 비선형 왜곡을 발생시키며, 이는 6차 이상의 고차 비선형성을 야기한다는 가정을 기반으로 한다. 고차 스펙트럼 분석(HOSA) 중 3차 누적량을 2차원 푸리에 변환한 바이코히런스를 핵심 특징량으로 채택한다. 바이코히런스는 입력 신호가 순수 톤일 때 발생하는 고조파와 상호조화(Inter‑Modulation, IM) 왜곡을 정량화할 수 있으며, 비선형 시스템을 통과한 신호는 특정 주파수 쌍에서 높은 바이코히런스 크기와 0 또는 π/2에 가까운 위상 특성을 보인다.
제안된 탐지 프레임워크는 세 가지 통계적 지표를 결합한다. 첫째, QPC(Quadratic Phase Coupling) 값으로 IM 왜곡 정도를 측정한다. 둘째, Hinich의 Gaussianity 테스트를 통해 3차 누적량이 0이 아닌지를 확인함으로써 신호의 비가우시안성을 판단한다. 셋째, Linear‑ity 테스트를 적용해 바이코히런스가 일정한 상수인지, 변동성을 보이는지를 검증한다. 이러한 비학습 기반 접근은 대규모 라벨링 데이터가 필요 없는 장점을 가지며, 실시간 구현이 비교적 용이하다.
실험에서는 12개의 원본 명령어를 각각 1차, 2차 재생(총 24개의 재생 음성)으로 구성하고, 1024‑point FFT와 Rao‑Gabr 윈도우를 사용해 50% 오버랩으로 바이코히런스를 추정하였다. 결과는 재생 음성에서 바이코히런스 크기가 원본 대비 현저히 증가하고, 위상 분포가 특정 주파수 대역에서 0·π/2에 집중되는 것을 보여준다. 또한 Gaussianity와 Linear‑ity 테스트 결과, 재생 음성은 비가우시안·비선형 특성을 명확히 나타내어 제안된 검출 기준에 부합하였다.
이와 같은 결과는 기존의 머신러닝 기반 스펙트럼 특징(예: MFCC, CQCC 등)과 달리, 물리적 비선형 왜곡을 직접 모델링함으로써 재생 공격을 보다 근본적으로 탐지할 수 있음을 시사한다. 그러나 논문은 다음과 같은 한계도 가지고 있다. 첫째, 실험 환경이 제한적이며, 다양한 스피커 모델·마이크 품질·방음 조건에서의 일반화 검증이 부족하다. 둘째, 고차 비선형 모델링이 실제 복합적인 채널(예: 압축 코덱, 네트워크 지연)까지 포괄하는지는 추가 연구가 필요하다. 셋째, 비학습 기반이므로 복잡한 공격(예: 합성 음성 + 재생)이나 적응형 공격에 대한 내성은 아직 검증되지 않았다.
종합적으로, 본 논문은 스마트 스피커의 구조적 취약성을 실증하고, 고차 스펙트럼 분석을 활용한 비학습 기반 재생 공격 탐지 기법을 제안함으로써, 향후 음성 기반 인증 시스템 설계에 중요한 참고 자료가 될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기