빅데이터 기반 재료 과학과 FAIR 데이터 인프라
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
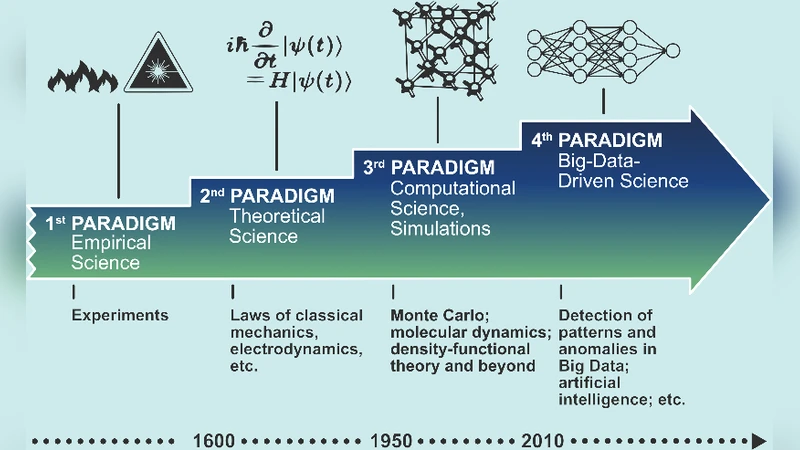
본 장에서는 재료 연구의 네 번째 패러다임인 빅데이터 기반 재료 과학을 소개하고, FAIR 원칙(Findable, Accessible, Interoperable, Re‑usable)을 기반으로 한 데이터 인프라의 필요성을 강조한다. 오픈 데이터와 고성능 컴퓨팅 코드 생태계가 결합될 때 인공지능이 대규모 데이터에서 새로운 물질 설계 규칙을 발견할 수 있음을 설명한다.
상세 분석
본 논문은 재료 과학이 실험·이론·시뮬레이션의 3단계 패러다임을 넘어, 데이터 중심의 네 번째 패러다임으로 전환하고 있음을 체계적으로 정리한다. 핵심은 ‘빅데이터’를 어떻게 수집·정제·공유·활용하느냐이며, 이를 위해 FAIR 원칙을 데이터 라이프사이클 전반에 적용한다는 점이다.
-
FAIR 원칙 적용 메커니즘
- Findable: 메타데이터 표준화와 고유 식별자(예: DOI, UUID) 부여를 통해 데이터셋을 검색 엔진에 노출한다.
- Accessible: 인증·인가 체계와 함께 HTTP/HTTPS, S3, Globus 등 표준 프로토콜을 이용해 언제 어디서든 접근 가능하도록 설계한다.
- Interoperable: Materials Project, OQMD, AFLOW 등 기존 데이터베이스와의 스키마 매핑을 위해 JSON‑LD, HDF5, CIF 등 포맷을 채택하고, 온톨로지를 활용해 의미적 호환성을 확보한다.
- Reusable: 데이터 품질 보증(버전 관리, 검증 워크플로우)과 라이선스 명시(Open Data Commons, CC‑BY)로 재사용 장벽을 최소화한다.
-
데이터 인프라와 생태계
- 논문은 ‘데이터 레이크’, ‘데이터 파이프라인’, ‘데이터 카탈로그’라는 3계층 구조를 제안한다. 데이터 레이크는 원시 계산·실험 결과를 원형 그대로 저장하고, 파이프라인은 자동화된 정제·표준화·인덱싱을 수행한다. 카탈로그는 메타데이터 검색과 사용자 정의 쿼리를 지원한다.
- 코드 생태계는 VASP, Quantum ESPRESSO, LAMMPS 등 전통적인 전자·원자 시뮬레이션 툴과, pymatgen, ASE, FireWorks 같은 워크플로우 관리 툴을 포함한다. 이러한 툴은 FAIR‑compatible API와 연동돼 데이터 생성·소비를 원활히 한다.
-
AI·ML 적용 사례
- 고차원 특성(구조, 전자 밴드, 열역학적 안정성 등)을 벡터화한 ‘표현학습’이 재료 성능 예측에 활용된다. 특히, 그래프 신경망(GNN)과 변분 오토인코더(VAE)가 대규모 데이터셋에서 물질 간 유사성을 학습해, 기존 고처리량(HT) 스크리닝으로는 놓친 ‘희귀한’ 후보를 제시한다.
- ‘활성 학습(active learning)’ 루프를 통해 모델이 불확실성이 큰 영역을 자동으로 선택하고, 추가 DFT 계산을 수행해 데이터베이스를 순환적으로 확장한다. 이는 계산 비용을 크게 절감하면서 탐색 효율을 높인다.
-
현안과 과제
- 데이터 표준화 부재와 메타데이터 품질 불균형이 여전히 큰 장애물이다. 특히, 실험 데이터는 포맷이 다양하고, 재현성 정보가 누락되는 경우가 많다.
- 프라이버시·지적 재산권 문제는 오픈 데이터와 상충한다. 논문은 ‘신뢰 가능한 공유(trusted sharing)’ 모델을 제시하며, 블록체인 기반 데이터 무결성 검증과 계약 기반 접근 제어를 논의한다.
- AI 모델의 ‘해석 가능성’이 부족해, 물리적 인사이트를 도출하기 어렵다. 이를 해결하기 위해 물리‑제한 학습(physics‑informed ML)과 모델 설명 기법(SHAP, LIME) 도입이 필요하다.
전반적으로, 본 논문은 재료 과학이 데이터와 인공지능을 중심으로 재편되는 과정을 체계적으로 정리하고, FAIR 데이터 인프라가 그 핵심 촉매 역할을 할 것임을 설득력 있게 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기