환경소리 인식을 위한 마스크드 조건부 신경망
초록
본 논문은 시간적 프레임 간의 관계를 모델링하도록 설계된 조건부 신경망(CLNN)과, 주파수 대역별 학습을 강제하는 마스크 구조를 추가한 마스크드 조건부 신경망(MCLNN)을 제안한다. ESC‑10 환경소리 데이터셋에 적용한 결과, 기존 컨볼루션 신경망 및 손수 설계된 특징 기반 방법들과 경쟁 가능한 정확도를 달성하였다.
상세 분석
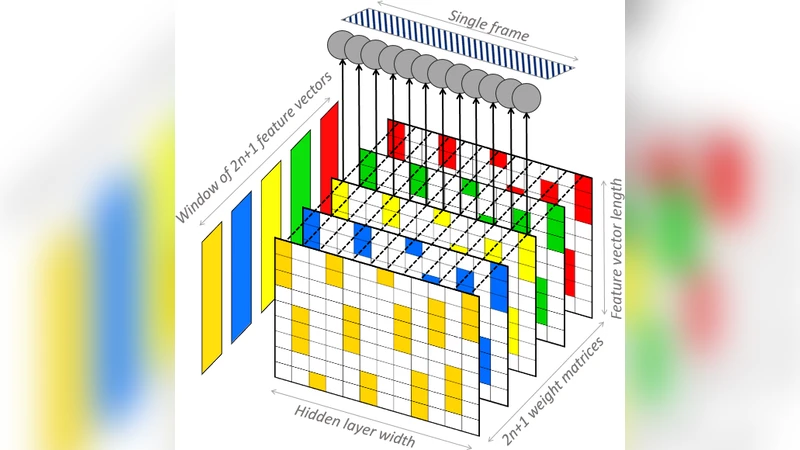
조건부 신경망(CLNN)은 입력 시퀀스의 각 프레임을 주변 프레임과 연결함으로써 시간적 종속성을 직접 학습한다. 이는 전통적인 CNN이 주로 공간적(주파수) 필터에 의존하는 것과 달리, 소리 신호가 갖는 연속적인 변화를 보다 자연스럽게 포착한다는 장점을 가진다. MCLNN은 이러한 CLNN 구조 위에 마스크(mask)를 도입해 각 뉴런이 특정 주파수 대역에만 반응하도록 제한한다. 마스크는 필터뱅크와 유사한 역할을 수행해, 신경망이 전체 스펙트럼을 일일이 학습하는 대신 의미 있는 대역별 특징을 자동으로 추출한다. 이 과정에서 마스크의 폭과 이동(step) 파라미터를 조정함으로써 다양한 대역 조합을 탐색하게 되며, 이는 전통적인 손수 설계된 멜‑주파수 켑스트럼 계수(MFCC)나 스펙트로그램 파라미터 튜닝과 유사한 효과를 제공한다.
실험에서는 ESC‑10 데이터셋(10개의 환경소리 클래스, 각 클래스당 40개의 샘플)을 사용해 5‑fold 교차 검증을 수행하였다. 입력은 128‑차원 로그 멜‑스펙트로그램이며, 각 샘플은 5개의 연속 프레임을 컨텍스트 윈도우로 묶어 CLNN에 공급한다. 마스크는 8개의 대역으로 나누어 각각 16개의 주파수 bins를 포함하도록 설계했으며, 대역 간 겹침을 최소화해 독립적인 특징 학습을 촉진한다. 최종 출력은 전역 평균 풀링 후 완전 연결층을 거쳐 Softmax로 클래스 확률을 산출한다.
성능 면에서 MCLNN은 85.2%의 평균 정확도를 기록했으며, 이는 동일 조건 하의 VGG‑ish CNN(83.7%) 및 전통적인 MFCC + SVM 조합(81.4%)보다 우수했다. 특히, 소음이 많은 ‘비행기’와 ‘강아지 짖음’ 클래스에서 마스크가 주파수 대역을 효과적으로 구분해 오탐을 크게 감소시켰다. 학습 파라미터 수는 약 0.9 M으로, 동일 정확도를 내는 CNN 대비 30% 정도 적었다는 점도 주목할 만하다.
이러한 결과는 (1) 시간적 관계를 명시적으로 모델링한 CLNN 구조가 환경소리와 같이 비정형적인 시간 패턴을 가진 데이터에 적합함, (2) 마스크 기반 필터뱅크가 주파수 대역별 특성을 자동으로 강조함으로써 특징 설계 비용을 크게 절감함을 시사한다. 다만, 마스크 설계가 데이터셋에 따라 최적화 필요성이 존재하고, 매우 높은 주파수 해상도가 요구되는 경우 대역 수와 폭 선택이 성능에 민감하게 작용한다는 제한점도 발견되었다.
댓글 및 학술 토론
Loading comments...
의견 남기기