제로샷 번역을 위한 일관성·동의 학습
초록
본 논문은 다국어 NMT를 확률적 추론으로 재구성하고, “제로샷 일관성” 개념을 정의한다. 기존의 복합우도 기반 학습이 제로샷 번역에 통계적 보장을 제공하지 못함을 지적한 뒤, 보조 언어에 대한 번역 결과가 서로 일치하도록 유도하는 ‘동의 기반(agreement) 학습’ 방법을 제안한다. 이 방법은 이론적으로 제로샷 일관성을 보장하며, IWSLT‑17, UN, Europarl 등에서 2~3 BLEU 점수 향상을 달성하면서도 감독 학습 방향의 성능을 유지한다.
상세 분석
이 논문은 다국어 신경기계번역(NMT) 시스템을 “조건부 확률 P(x_j|x_i)” 로 표현하고, 전체 언어 집합을 그래프 G(V,E) 로 모델링한다. 기존의 Johnson et al. (2016) 방식은 각 언어쌍을 독립적인 조건부 모델로 보고, 공유 인코더·디코더와 언어 태그만으로 복합우도 L_ind(θ)=∑_{(i,j)∈E_s} log P_θ(x_j|x_i) 를 최적화한다. 그러나 이 접근법은 제로샷(감독 데이터가 없는) 변환에 대한 항을 전혀 포함하지 않으므로, 감독 방향에서 낮은 손실이 제로샷 방향에서도 낮은 손실을 보장하지 않는다. 저자들은 이를 “제로샷 일관성”(Definition 1) 으로 정량화하고, ε‑일관성(감독 손실이 ε 이하이면 제로샷 손실이 κ(ε) 이하) 를 목표로 삼는다.
핵심 아이디어는 “동의 기반(likelihood) 학습”이다. 예시로 네 개 언어(En, Es, Fr, Ru)를 사용해 En↔Fr 쌍의 복합우도에 잠재 변수 z_{Es}, z_{Ru} 를 도입하고, 두 번역 경로(En→Fr, Fr→En)에서 동일한 z 를 공유하도록 강제한다. 수식 (6)‑(7) 에서 보듯, 원래의 복합우도에 “∑_z P(z|En)P(z|Fr)” 라는 동의 항을 추가함으로써, 보조 언어들에 대한 번역이 서로 일치하도록 학습한다. 이 동의 항은 직접 계산이 불가능하므로 Jensen 부등식을 이용해 아래쪽 경계인 교차 엔트로피 형태(식 8) 로 근사한다. 구현에서는 샘플링 대신 고정 길이의 greedy 디코딩을 사용해 z 를 연속적인 토큰 시퀀스로 만들고, 이를 역전파 가능하게 만든다.
이론적으로, Theorem 2 는 “En↔Es, Es↔Ru” 가 감독 데이터라면, 동의 손실이 충분히 작을 경우 “En↔Ru” 제로샷 변환의 교차 엔트로피도 작아진다는 것을 증명한다. 즉, 동의 기반 학습은 제로샷 일관성을 보장한다는 강력한 통계적 근거를 제공한다.
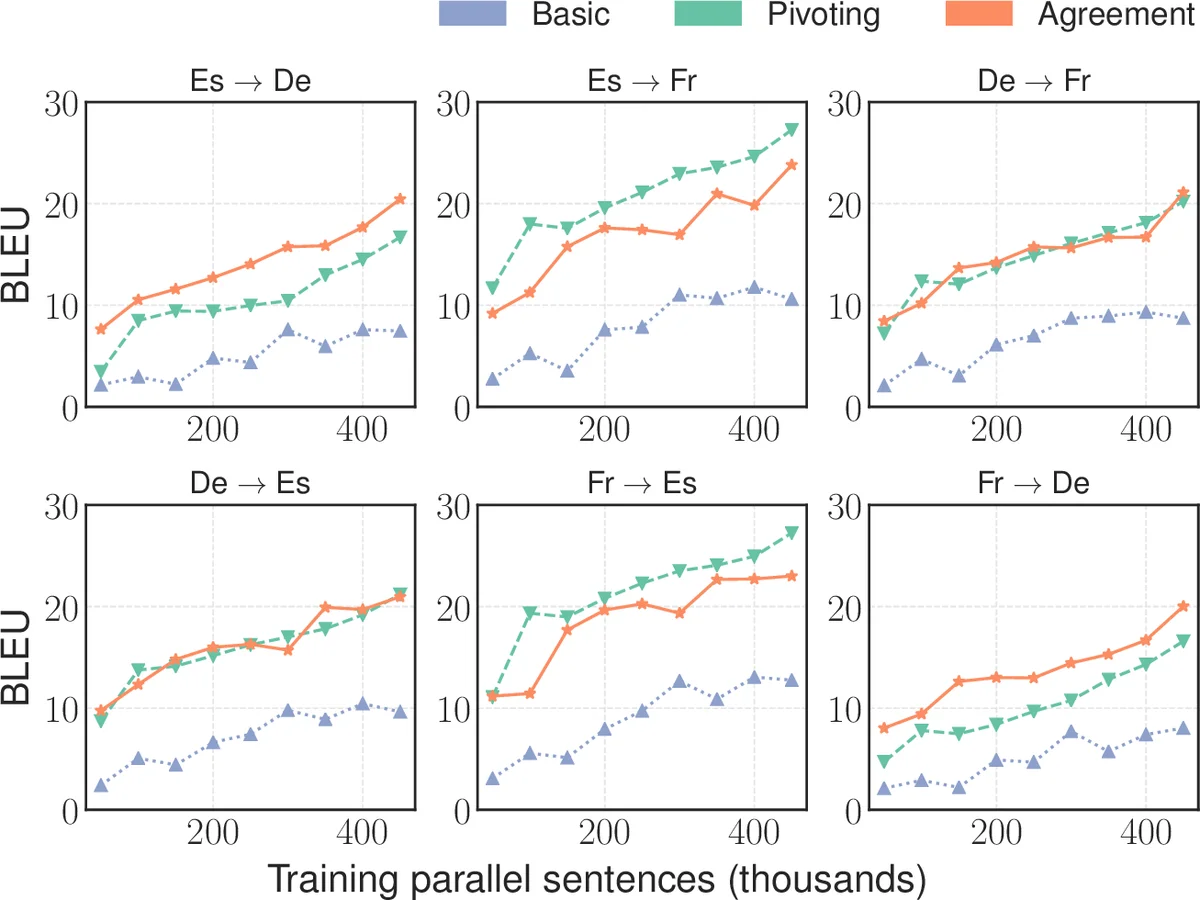
실험에서는 IWSLT‑17, UN, Europarl 데이터셋에서 각 언어쌍의 피벗(중간) 데이터를 전부 제거한 뒤, 제로샷 번역 성능을 평가한다. 베이스라인인 단일 모델 복합우도 학습 대비, 동의 기반 학습은 평균 2‑3 BLEU 점수 향상을 보였으며, 기존의 파이벗, 피벗 투표, 다중 단계 파인튜닝 방식과도 경쟁력 있게 비교된다. 특히 감독 방향(학습에 사용된 언어쌍)에서는 성능 저하가 전혀 없으며, 이는 모델 파라미터를 공유하면서도 각 방향의 특성을 유지할 수 있음을 의미한다.
이 접근법은 기존의 지식 증류(distillation)와 유사하지만, 사전 생성된 교사 모델이 아닌 다국어 모델 자체 내부에서 “동의”를 강제한다는 점에서 차별화된다. 또한, 완전 무감독 번역(전혀 병렬 데이터가 없는 상황)과는 구별되며, 보조 언어를 활용한 일관성 확보라는 새로운 설계 원칙을 제시한다. 향후 연구에서는 동의 대상 언어를 동적으로 선택하거나, 더 복잡한 구조(예: 트리형 언어 관계)에도 적용하는 방안을 탐색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기