짧은 발화 보상을 위한 코사인 기반 교사학생 학습
초록
본 논문은 2초 이하의 짧은 발화에서도 텍스트‑독립 화자 검증 성능을 유지하기 위해, 화자 임베딩 추출 과정 전체에 걸쳐 보상을 수행하는 교사‑학생(Teacher‑Student) 학습 프레임워크를 제안한다. 음성 파형을 직접 입력으로 사용하고, CNN‑GRU 구조에서 130 ms 단위의 음운‑레벨 특징을 추출한 뒤, 새로운 손실 함수(코사인 거리와 KL‑다이버전스 결합)를 적용해 짧은 발화의 임베딩을 긴 발화와 정렬한다. VoxCeleb1 실험에서 짧은 발화에 의한 EER 악화를 약 65 % 회복하였다.
상세 분석
이 연구는 화자 검증 시스템에서 가장 흔히 발생하는 “짧은 발화에 의한 성능 저하” 문제를 근본적으로 해결하고자 한다. 기존 방법들은 주로 i‑vector 혹은 사후에 변환 네트워크를 이용해 긴 발화와 짧은 발화 사이의 매핑을 시도했으며, 이는 발화 수준의 특징을 이미 추출한 뒤에 보정을 수행하기 때문에 음운‑레벨 정보 손실을 완전히 복구하지 못한다는 한계가 있었다. 논문은 이러한 한계를 인식하고, 보정을 화자 임베딩을 생성하는 전체 파이프라인, 특히 CNN‑GRU 구조의 중간 단계인 “음운‑레벨 특징”(≈130 ms 구간)에서 수행한다는 점에서 차별화된다.
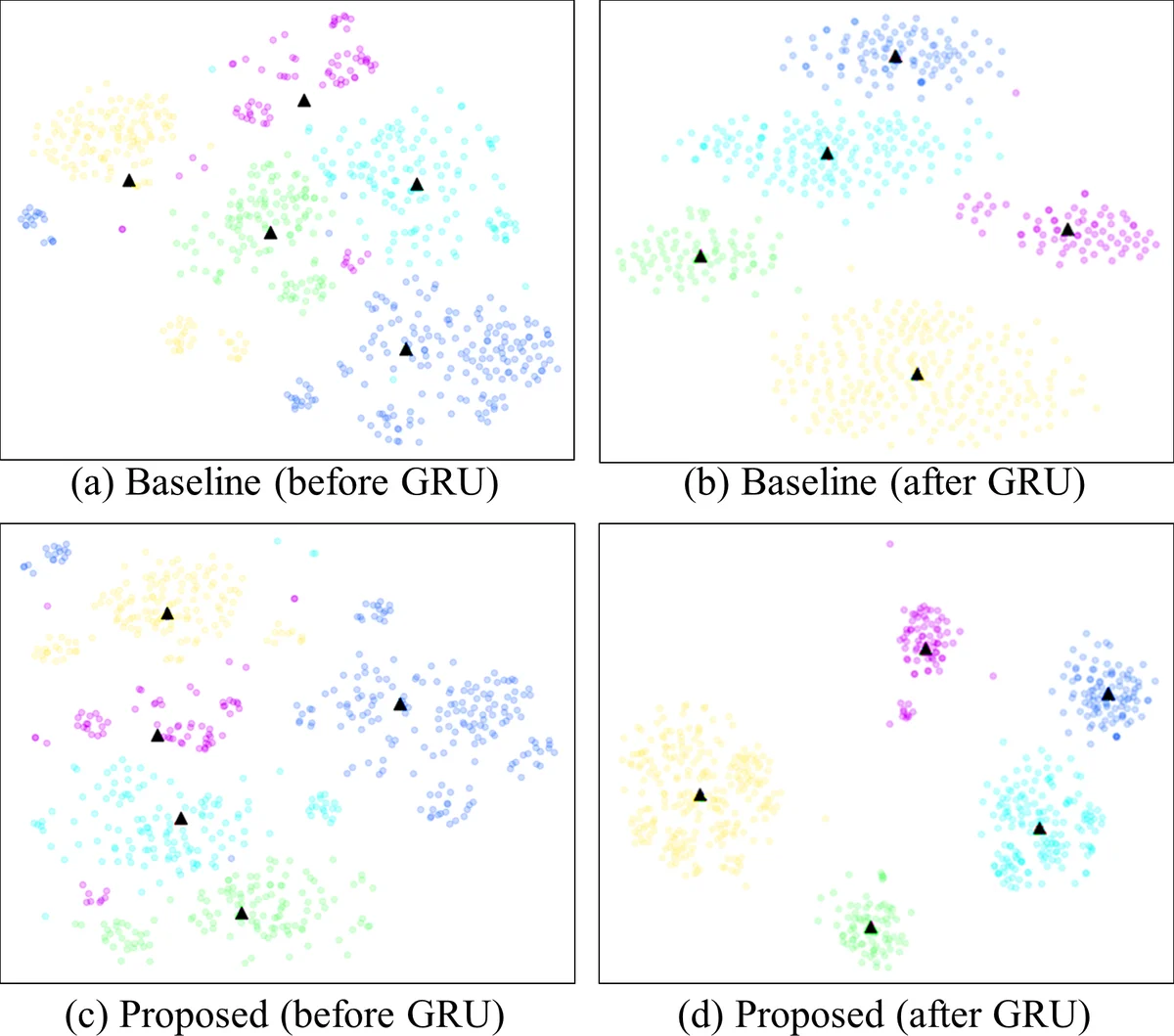
CNN 블록은 원시 파형을 직접 처리하며, 스트라이드와 풀링을 통해 입력 길이에 따라 동적으로 변하는 시퀀스 길이(예: 3.59 s → 27개, 2.05 s → 15개)를 만든다. 이 시퀀스는 GRU 레이어에 전달되어 발화‑레벨 임베딩을 생성한다. 여기서 핵심은 교사‑학생 학습을 적용해, 동일한 화자·발화에 대해 긴 버전(teacher)과 짧은 버전(student)의 출력 분포를 맞추는 동시에, 임베딩 공간 자체도 코사인 거리 혹은 MSE로 정렬한다는 점이다. 손실 함수는
Loss = Σ_j Dist( e_T , e_S ) – Σ_j Σ_i p_T(s_i|x_j^l) log p_S(s_i|x_j^sh)
형태로, 첫 번째 항은 임베딩 정렬을, 두 번째 항은 출력 레이어의 확률 분포 일치를 강제한다. 이렇게 하면 짧은 발화가 긴 발화와 동일한 화자 정보를 담도록 강제하면서도, 분류 경계(softmax)에서의 판별력은 유지된다.
실험에서는 VoxCeleb1 데이터셋을 사용해 3.59 s와 2.05 s 두 길이로 평가하였다. 기본 R‑CNN‑GRU 모델은 2.05 s에서 EER 12.80 %를 기록했으며, 이는 3.59 s 기준 대비 46 % 악화된 것이다. 제안된 TS 학습을 적용한 모델은 코사인 거리와 KL‑다이버전스를 동시에 사용했을 때 EER 8.72 %로 회복했으며, 이는 약 65 %의 성능 손실을 보상한 결과이다. 또한, 단순히 출력 레이어 KL만 사용하거나, 임베딩 거리만 사용했을 때보다 두 손실을 결합했을 때 가장 큰 개선을 보였다.
이 접근법의 장점은 (1) 별도의 보정 모듈이 필요 없으며, 전체 네트워크가 하나의 엔드‑투‑엔드 모델로 동작한다는 점, (2) 음운‑레벨 특징을 직접 활용함으로써 짧은 발화에서도 충분한 음성학적 정보를 보존한다는 점, (3) 손실 함수 설계가 임베딩 정렬과 판별력 유지라는 두 목표를 동시에 최적화한다는 점이다. 한계로는 현재 실험이 VoxCeleb1 단일 데이터셋에 국한되어 있어, 다른 언어·채널 조건에서의 일반화 검증이 필요하고, GRU 대신 Transformer 기반 시퀀스 모델을 적용했을 때의 효과는 아직 조사되지 않았다. 향후 연구에서는 다중 언어·다중 채널 데이터, 실시간 스트리밍 환경, 그리고 더 얕은 혹은 더 깊은 CNN‑GRU 변형을 탐색함으로써 실제 서비스 적용 가능성을 높일 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기