클라우드와 포그 컴퓨팅의 비교와 미래 전망
초록
본 논문은 포그 컴퓨팅의 개념과 활용 사례를 소개하고, 전통적인 클라우드 컴퓨팅과의 차이점을 기능·보안·대역폭 측면에서 비교한다. 포그는 네트워크 가장자리에서 연산·저장·분석을 수행함으로써 지연 시간을 최소화하고, 제한된 대역폭 환경에서도 효율적인 데이터 처리를 가능하게 한다. 논문은 포그가 빅데이터, 사물인터넷(IoT), 실시간 제어 시스템 등에 적합하며, 클라우드와 상호 보완적인 구조를 이루어야 함을 강조한다.
상세 분석
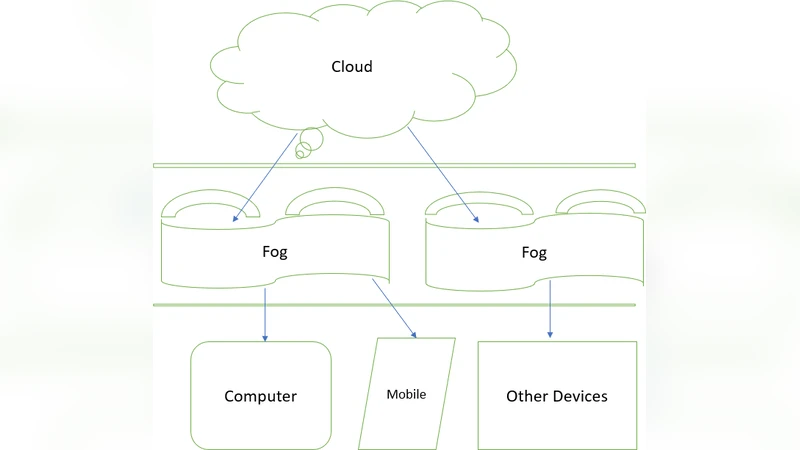
이 논문은 포그 컴퓨팅을 “클라우드와 네트워크 가장자리 사이에 위치하는 분산형 컴퓨팅 인프라”로 정의하고, 기존 클라우드 모델이 중앙집중식 데이터 센터에 의존해 높은 처리 능력과 확장성을 제공하는 반면, 지연 시간과 대역폭 제약으로 실시간 응용에 한계가 있음을 지적한다. 포그는 라우터, 스위치, 모바일 기기, 엣지 서버 등 다양한 노드에 컴퓨팅 자원을 배치함으로써 데이터가 발생한 지점에서 바로 전처리·필터링·분석을 수행한다. 이로써 전체 데이터를 클라우드로 전송할 필요가 줄어들어 네트워크 트래픽이 감소하고, 민감한 데이터는 로컬에서 암호화·보안 정책을 적용할 수 있어 개인정보 보호 수준이 향상된다.
논문은 포그와 클라우드의 기능적 차이를 네 가지 축으로 정리한다. 첫째, 지연 시간: 포그는 수 밀리초 수준의 응답을 보장해 자율주행, 스마트 제조, 원격 의료 등 초실시간 요구사항을 충족한다. 둘째, 대역폭 효율: 데이터 전처리와 압축을 엣지에서 수행함으로써 백본 네트워크에 전송되는 데이터 양을 최소화한다. 셋째, 보안·프라이버시: 데이터가 로컬에 머무는 비율이 높아지면 전송 중 탈취 위험이 감소하고, 지역별 규제(예: GDPR, 데이터 주권)에 맞춘 정책 적용이 용이해진다. 넷째, 확장성·유연성: 포그 노드는 동적으로 추가·제거가 가능해 급격한 트래픽 변동에 빠르게 대응한다.
하지만 포그가 완전한 대체 기술이 아니라는 점도 강조한다. 포그 노드는 제한된 연산·스토리지·전력 자원을 갖고 있어 복잡한 머신러닝 모델 학습이나 대규모 데이터 집계는 여전히 클라우드가 담당한다. 따라서 하이브리드 아키텍처가 최적의 솔루션으로 제시된다. 데이터는 엣지에서 1차 처리·이벤트 감지 후, 필요 시 클라우드로 전송해 장기 저장·심층 분석·전역 서비스 제공에 활용한다.
또한, 포그 구현 시 고려해야 할 기술적 과제로는 노드 관리·오케스트레이션, 표준화된 인터페이스, 보안 키 관리, 리소스 스케줄링 등이 있다. 현재 OpenFog Consortium와 ETSI MEC와 같은 표준화 기구가 API와 서비스 모델을 정의하고 있으나, 상호 운용성 확보와 벤더 종속성 해소는 여전히 과제로 남아 있다.
결론적으로, 논문은 포그 컴퓨팅이 클라우드의 한계를 보완하고, 특히 IoT와 실시간 서비스가 급증하는 환경에서 필수적인 인프라 계층으로 부상할 것이라고 전망한다. 포그와 클라우드의 협업 모델을 설계할 때는 응용 요구사항(지연, 보안, 데이터 양)과 인프라 제약(노드 능력, 관리 복잡도)을 균형 있게 평가해야 함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기