CHiME‑5를 위한 스피커‑인식 기반 단일 모델 분리와 향상된 빔포밍 기법
초록
본 논문은 CHiME‑5 데이터셋의 복잡한 회의 환경에서 스피커‑의존 분리를 개선하기 위해 i‑vector 기반 스피커‑인식 학습, GWPE·CGMM·OMLSA 전처리, 그리고 GEV 빔포밍을 결합한 파이프라인을 제안한다. 단일 통합 마스크 추정 모델만으로도 개발 셋에서 WER를 80.28%에서 60.15%까지 20%p 절감했으며, 기존 제출 시스템 대비 연산 복잡도도 크게 낮추었다.
상세 분석
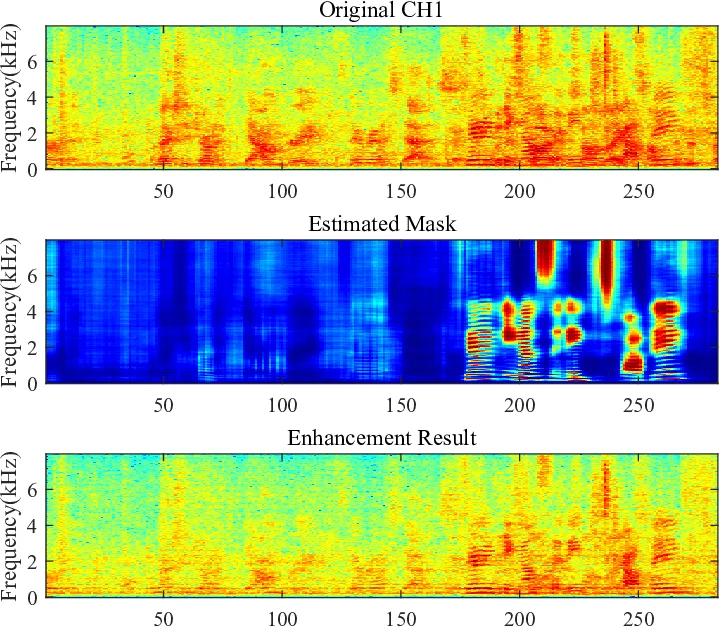
이 연구는 CHiME‑5와 같이 다중 마이크, 고도 겹침, 비정상적인 잡음·리버버레이션이 존재하는 실내 대화 데이터를 대상으로, 전통적인 스피커‑독립 분리 방식이 갖는 한계를 극복하고자 한다. 핵심 아이디어는 ‘스피커‑인식’(speaker‑aware) 학습으로, 각 발화에 대한 i‑vector를 보조 입력으로 사용해 목표 스피커의 마스크를 직접 예측하도록 네트워크를 유도한다. 이를 위해 먼저 비겹침 구간을 추출하고, GWPE로 초기 리버버레이션을 감소시킨 뒤, 복소 가우시안 혼합 모델(CGMM) 기반의 마스크를 통해 MVDR 빔포밍을 수행한다. 이 과정에서 얻어진 고품질 ‘청정’ 신호를 OMLSA로 추가 디노이징함으로써, 학습용 IRM/PSM 타깃 마스크의 SNR을 크게 향상시켰다.
네트워크 구조는 2‑layer TDNN 뒤에 BLSTM을 배치하고, 두 번째 TDNN 레이어와 BLSTM 레이어에 i‑vector를 연결(concatenate)하여 스피커 특성을 효과적으로 주입한다. 마스크 손실은 MSE 기반이며, IRM과 정규화된 PSM 두 종류를 실험하였다. PSM은 무한대 값을 갖는 문제를 0‑1 구간으로 클리핑해 안정성을 확보하였다.
빔포밍 단계에서는 기존 MVDR 대신 GEV 빔포머를 적용했는데, GEV는 스피커 마스크의 정확도에 민감하게 반응한다. 실험 결과, GWPE‑SA++(i‑vector+PSM) 모델에 GEV 빔포머를 결합했을 때 전체 평균 WER가 61.31%까지 감소했으며, 특히 뒤쪽 방(Kitchen) 스피커에서 큰 개선을 보였다. 이는 GEV가 스피커‑특정 마스크를 이용해 목표 방향의 신호 대 잡음비를 최적화함을 의미한다.
음향 모델 측면에서는 기존 9‑TDNN 기반 시스템에 비해, TDNN‑F와 CNN‑TDNN‑F 구조를 도입해 LF‑MMI 학습을 수행하였다. 리버버레이션 데이터와 전처리된 강화 데이터를 추가 학습에 활용함으로써, 기본 80.28%에서 70.02%까지, 최종적으로는 60.15%까지 WER를 낮출 수 있었다.
전체 파이프라인은 (1) 비겹침 구간 추출 → GWPE → CGMM‑MVDR → OMLSA, (2) i‑vector 기반 스피커‑인식 마스크 추정, (3) GEV 빔포밍, (4) 고성능 TDNN‑F 기반 음향 모델 순으로 구성된다. 이 구조는 단일 통합 마스크 모델만으로도 다중 스피커 상황을 효과적으로 처리하며, 별도의 스피커별 모델 학습이나 두 단계 분리 과정을 생략함으로써 계산 비용과 메모리 사용량을 크게 절감한다. 또한, 외부 데이터 사용이 금지된 CHiME‑5 규칙을 준수하면서도 실험적으로 입증된 데이터 처리와 모델링 기법을 결합해 실제 환경에서의 적용 가능성을 높였다.
댓글 및 학술 토론
Loading comments...
의견 남기기