GPU 그래프 처리 효율을 높이는 캐시 중심 최적화 프레임워크 GraphCage
초록
GraphCage는 GPU의 마지막 레벨 캐시(LLC)를 활용한 정적 캐시 차단 기법인 TOCAB(Throughput‑Oriented Cache Blocking)를 제안한다. TOCAB는 push와 pull 양방향 모두에서 부분 그래프를 캐시 친화적으로 분할하고, 서브그래프의 희소성을 고려한 로드 밸런싱과 결합한다. 이를 통해 기존 CuSha·Gunrock 대비 2~4배의 속도 향상과 메모리 사용량 감소를 달성한다.
상세 분석
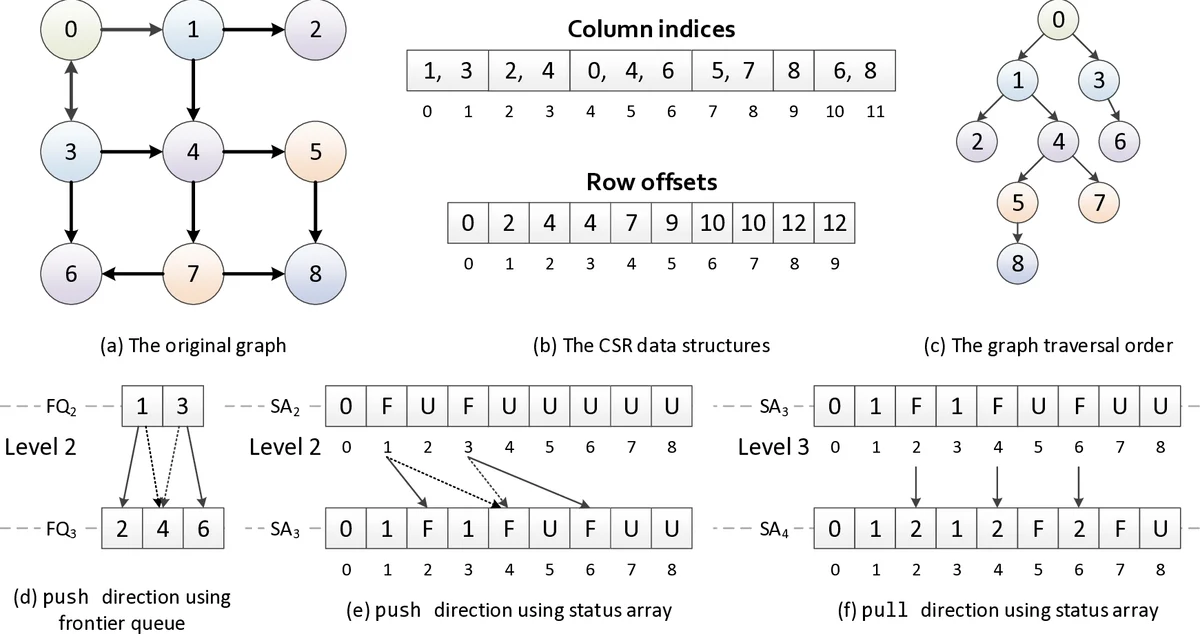
본 논문은 GPU 기반 그래프 처리에서 가장 큰 병목인 메모리 접근 지연을 캐시 차단을 통해 완화하고자 한다. 기존의 GPU 그래프 프레임워크는 워크 효율성, 동기화 오버헤드, 로드 불균형을 주로 해결했지만, 데이터 지역성 향상에는 한계가 있었다. 특히 CuSha는 공유 메모리 기반 샤드 분할을 사용했지만, 샤드 크기가 작아 병합 비용이 크게 발생하고, CSR가 아닌 COO 형태를 사용해 메모리 사용량이 2.5배 증가한다는 단점이 있었다.
GraphCage는 이러한 문제점을 보완하기 위해 세 가지 핵심 설계를 도입한다. 첫째, TOCAB는 정적 캐시 차단 스킴으로, 그래프를 일정 크기의 블록으로 나누어 LLC에 적재될 수 있게 한다. 블록 내부에서는 전역 합산을 위한 희소 접근을 피하고, 부분 합산을 밀집 형태로 저장해 메모리 트래픽을 감소시킨다. 둘째, TOCAB는 push와 pull 두 방향 모두에 적용 가능하도록 설계되었으며, 특히 pull 방향에서 토폴로지‑드리븐 커널에 적용함으로써 원자 연산 없이도 높은 워크 효율성을 유지한다. 셋째, 서브그래프의 희소성을 고려한 로드 밸런싱 전략을 결합한다. 고차원 정점(핵심 정점)의 경우 워프 단위, 블록 단위, 그리드 단위로 작업을 동적으로 할당해 워크로드 편차를 최소화한다. 또한, 탐색 기반 알고리즘(BFS, Betweenness Centrality 등)에서는 활성 정점 집합 크기에 따라 캐시 차단 적용 여부를 동적으로 판단한다.
실험에서는 최신 NVIDIA GPU(NVIDIA V100 기준)와 여러 실제 그래프(road, social, web)들을 대상으로 PageRank, BFS, SSSP, Betweenness Centrality 등을 평가하였다. 결과는 GraphCage가 CuSha 대비 평균 2.5배, Gunrock 대비 3.8배의 속도 향상을 보였으며, 메모리 사용량은 CuSha 대비 30% 정도 절감되었다. 특히 대규모 그래프에서 LLC 활용도가 크게 증가해 DRAM 접근이 현저히 감소했음이 확인되었다.
한계점으로는 정적 차단 크기 선택이 그래프 구조에 민감하며, 매우 작은 활성 집합을 갖는 초기 BFS 단계에서는 차단 오버헤드가 성능을 저하시킬 수 있다. 또한, 현재 구현은 CSR 기반 단일 GPU에 국한되어 있어 멀티‑GPU 확장성에 대한 추가 연구가 필요하다.
요약하면, GraphCage는 GPU의 캐시 구조를 의도적으로 설계에 반영함으로써 기존 최적화 기법과 시너지를 내는 새로운 접근법을 제시한다. 이는 앞으로 GPU 기반 대규모 그래프 분석 시스템에서 데이터 지역성 향상을 위한 중요한 설계 패러다임이 될 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기