산업 현장에서 소프트웨어 제품 라인 채택을 위한 체계적 문헌 검토 프로토콜
초록
본 논문은 산업 현장에서 소프트웨어 제품 라인 엔지니어링(SPLE) 채택의 장·단점을 파악하기 위한 체계적 문헌 검토(SLR) 프로토콜을 상세히 제시한다. 목표, 연구 질문, 검색 전략(수동·자동·스노우볼링), 선정 기준, 품질 평가, 데이터 추출 절차 등을 구체화하고, 연구 재현성을 확보한다.
상세 분석
이 논문은 증거 기반 소프트웨어 공학(EBSE)의 핵심 방법론인 체계적 문헌 검토(SLR)와 체계적 매핑 연구(SMS)의 차이를 명확히 설명하고, 특히 SPLE(Software Product Line Engineering)의 산업 적용 사례에 초점을 맞춘다. 연구 목표는 “산업 개발 맥락에서 SPLE 채택이 가져온 이점과 문제점을 식별·분석”하는 것으로, 이를 위해 다섯 개의 주요 연구 질문(RQ1RQ5)과 세 개의 인구통계 질문(DQ1DQ3)을 설정한다.
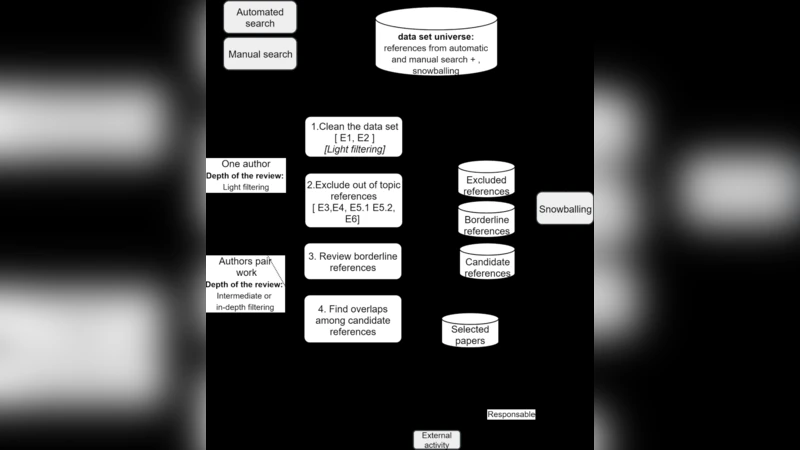
프로토콜 설계는 크게 7단계로 구성된다. 첫 번째 단계는 목표와 연구 질문 정의이며, 여기서 SPLE 채택 방식을 ‘프로액티브’, ‘리액티브’, ‘익스트랙티브’ 세 가지로 구분하고 각각의 빈도와 연관성을 탐색한다. 두 번째 단계는 검색 전략으로, 수동 검색(핵심 학술대회·저널·전문 서적·웹사이트), 자동 검색(ACM DL, IEEE Xplore, SCOPUS, Web of Science) 및 스노우볼링(전·후방 인용) 세 가지 방법을 병행한다. 자동 검색에서는 PIC0 기법을 활용해 검색어를 체계적으로 구성하고, 3,000건 이하의 결과와 95% 회수율을 목표로 한다.
선정 과정은 네 가지 활동(데이터 정제, 주제 외 논문 제외, 경계 논문 검토, 중복 제거)과 여섯 개의 배제 기준(E1~E6)으로 엄격히 관리된다. 특히 E5와 E5.2는 ‘실제 산업 환경에서의 SPLE 적용 여부’를 중점적으로 판단하도록 설계돼, 학술적 시뮬레이션 논문을 효과적으로 차단한다. 선정된 논문은 품질 평가(QA) 단계에서 추가 필터링된 뒤, 데이터 추출 양식에 따라 연구 질문별로 정량·정성 데이터를 수집한다.
프로토콜의 장점은 재현성 확보와 편향 최소화에 있다. 모든 단계와 사용 도구(스프레드시트 템플릿, 검색 문자열, 배제 기준 표 등)를 명시함으로써 다른 연구자가 동일 절차를 따라 동일한 결과를 얻을 수 있다. 또한, 프로토콜은 유연성을 유지하도록 설계돼, 실행 중 발생하는 중대한 변동은 최종 보고서에 명시하도록 규정한다.
이 논문은 SPLE 채택에 관한 기존 2차 연구가 주로 학술적 제안에 머물러 있음을 지적하고, 산업 현장의 실제 경험을 체계적으로 정리하려는 시도이다. 따라서 향후 연구자는 이 프로토콜을 기반으로 실증 데이터를 수집·통합함으로써, SPLE 도입 비용, ROI, 제품 라인 규모, 조직 문화 변화 등 구체적 메트릭을 도출할 수 있다. 또한, 프로토콜에 포함된 인구통계 질문을 통해 연구 분야의 출판 경향, 주요 연구자·기관·국가를 파악하고, 연구 공백을 식별하는 데도 활용 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기