배치 크기가 GPU와 TPU 학습·추론 성능에 미치는 영향
초록
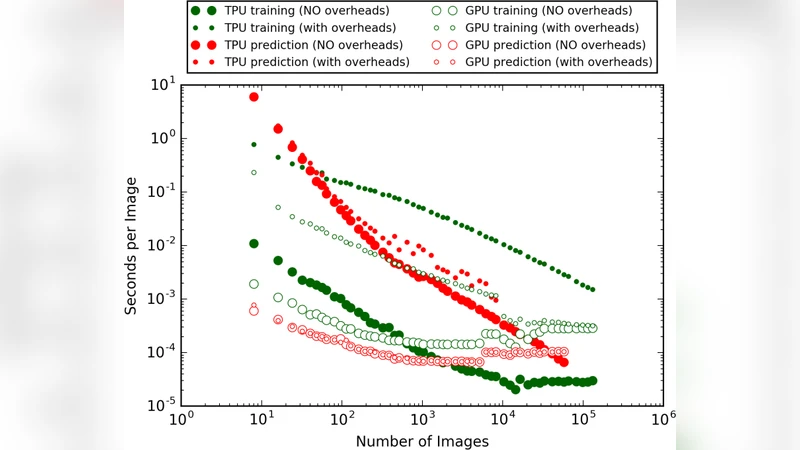
본 연구는 MNIST와 Fashion‑MNIST 데이터셋을 이용해 배치 크기를 최대화했을 때 NVIDIA Tesla K80 GPU와 Google TPU v2(8코어) 간의 학습 및 추론 속도 차이를 정량적으로 평가한다. 실험 결과, 배치가 512 이미지 이상이면 학습 단계에서 TPU가 GPU 대비 10배까지, 추론 단계에서는 2배까지 속도 향상을 보였으며, 정확도와 손실은 두 하드웨어 모두 3번째 유효숫자까지 동일하였다.
상세 분석
이 논문은 딥러닝 워크로드에서 배치 크기가 하드웨어 가속 효율에 미치는 영향을 체계적으로 조사한다는 점에서 의미가 크다. 먼저 실험에 사용된 모델은 2‑층 컨볼루션과 완전 연결층으로 구성된 비교적 단순한 DNN이며, 이는 학습·추론 시간을 빠르게 측정하면서도 MNIST·Fashion‑MNIST 수준의 정확도를 확보하도록 설계되었다. GPU는 NVIDIA Tesla K80을, TPU는 Google Cloud에서 제공되는 TPU v2 8코어를 각각 사용했으며, 두 환경 모두 Google Colab에서 동일한 파이썬/텐서플로우 스택으로 실행해 비교 가능성을 높였다.
배치 크기는 8부터 시작해 13 000까지 단계적으로 증가시켰고, 실제 메모리 한계에 도달하기 전까지는 인위적으로 이미지 복제를 통해 최대 배치를 만들었다. 실험에서는 “오버헤드 포함”과 “오버헤드 제외” 두 가지 런타임을 측정했는데, 첫 번째 에포크는 데이터 로딩·그래프 초기화 비용을 포함하고 두 번째 에포크는 순수 연산 시간만을 반영한다. 이를 통해 TPU가 초기 설정 비용에 민감하지만, 배치가 충분히 커지면 연산 효율이 급격히 상승한다는 점을 확인했다.
성능 측면에서 가장 눈에 띄는 결과는 배치가 512 이미지를 초과할 때부터 학습 단계에서 TPU가 GPU 대비 10배에 달하는 속도 향상을 보인 것이다. 이는 TPU가 700 MHz에서 65 536개의 8‑bit MAC 유닛을 동시에 동작시켜 높은 명령당 사이클(IPC)을 구현하기 때문이다. 반면, K80은 2개의 GK210 칩을 사용하지만 메모리 대역폭과 연산 유닛 수가 제한적이어서 대규모 배치 병렬화에 한계가 있다. 추론 단계에서는 배치가 40 000 이미지 이상일 때만 TPU가 GPU보다 2배 빠른 것으로 나타났으며, 이는 추론 시에도 데이터 전처리·전송 오버헤드가 전체 시간의 큰 비중을 차지하기 때문이다.
정확도와 손실은 두 하드웨어 모두 거의 동일했으며, MNIST에서는 0.99 ± 0.0004, Fashion‑MNIST에서는 0.92 ± 0.005 수준을 기록했다. 이는 8‑bit 정수 연산을 사용하는 TPU가 FP32 기반 GPU와 비교해 수치적 차이가 거의 없음을 시사한다. 또한 ROC‑AUC와 같은 평가 지표에서도 차이가 없었으므로, 성능 향상이 모델 품질에 부정적 영향을 미치지 않음을 확인했다.
하지만 연구에는 몇 가지 제한점이 있다. 첫째, 실험에 사용된 모델이 비교적 얕고 파라미터 수가 적어 대규모 네트워크(ResNet‑50, BERT 등)에서의 스케일링 효과를 일반화하기 어렵다. 둘째, 배치 크기를 인위적으로 늘리기 위해 이미지 복제를 사용했는데, 이는 실제 데이터 파이프라인에서 발생할 수 있는 I/O 병목을 충분히 반영하지 못한다. 셋째, TPU v2 8코어만 사용했으므로, 더 많은 코어(예: 128코어)나 최신 TPU v3/v4와의 비교는 추후 연구가 필요하다. 마지막으로, 오버헤드 측정이 에포크 단위로만 이루어졌기 때문에 초기 그래프 컴파일·컨테이너 시작 비용을 정확히 분리하기엔 한계가 있다.
이러한 한계를 감안하더라도, 본 논문은 배치 크기와 데이터 양이 충분히 클 때 TPU가 저비용 GPU 대비 뛰어난 연산 효율을 제공한다는 실증적 근거를 제시한다. 특히, 실시간 대규모 이미지 스트리밍(예: ADAS, 교통 감시)과 같이 높은 처리량이 요구되는 응용 분야에서 TPU 기반 파이프라인 설계의 가치를 강조한다. 향후 연구에서는 다양한 모델 아키텍처, 메모리 최적화 기법(양자화·프루닝) 및 최신 TPU·GPU 세대 간의 종합적인 벤치마크가 필요할 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기