PRADA: DNN 모델 도난 공격을 탐지하고 방어하다
본 논문은 머신러닝 모델의 비즈니스 가치와 보안 위험을 보호하기 위한 연구를 제시한다. 예측 API를 통한 새로운 DNN 모델 추출 공격 기법을 소개하고, 이 공격들의 효과를 높이는 핵심 통찰을 제공한다. 또한, 연속적인 API 쿼리 분포를 분석하여 이상 패턴을 탐지하는 최초의 일반적 방어 기법인 PRADA를 제안하며, 이 방어 기법이 기존 모든 공격을 오탐 없이 탐지할 수 있음을 실험을 통해 입증한다.
저자: Mika Juuti, Sebastian Szyller, Samuel Marchal
본 논문 "PRADA: Protecting against DNN Model Stealing Attacks"은 머신러닝, 특히 DNN 모델의 기밀성을 위협하는 모델 추출 공격에 대한 포괄적인 연구를 제시한다. 모델 추출 공격은 클라우드 예측 API(MLaaS) 또는 온디바이스 보호 환경에서도 공격자가 블랙박스 방식으로 모델을 반복 쿼리하여 그 기능을 복제하는 '대체 모델'을 만드는 공격이다. 이는 모델 자체의 지적 재산권을 훼손하거나, 대체 모델에서 생성된 '전이 가능한 적대적 예제'를 원본 모델을 공격하는 데 사용할 수 있다는 점에서 심각한 위협이다.
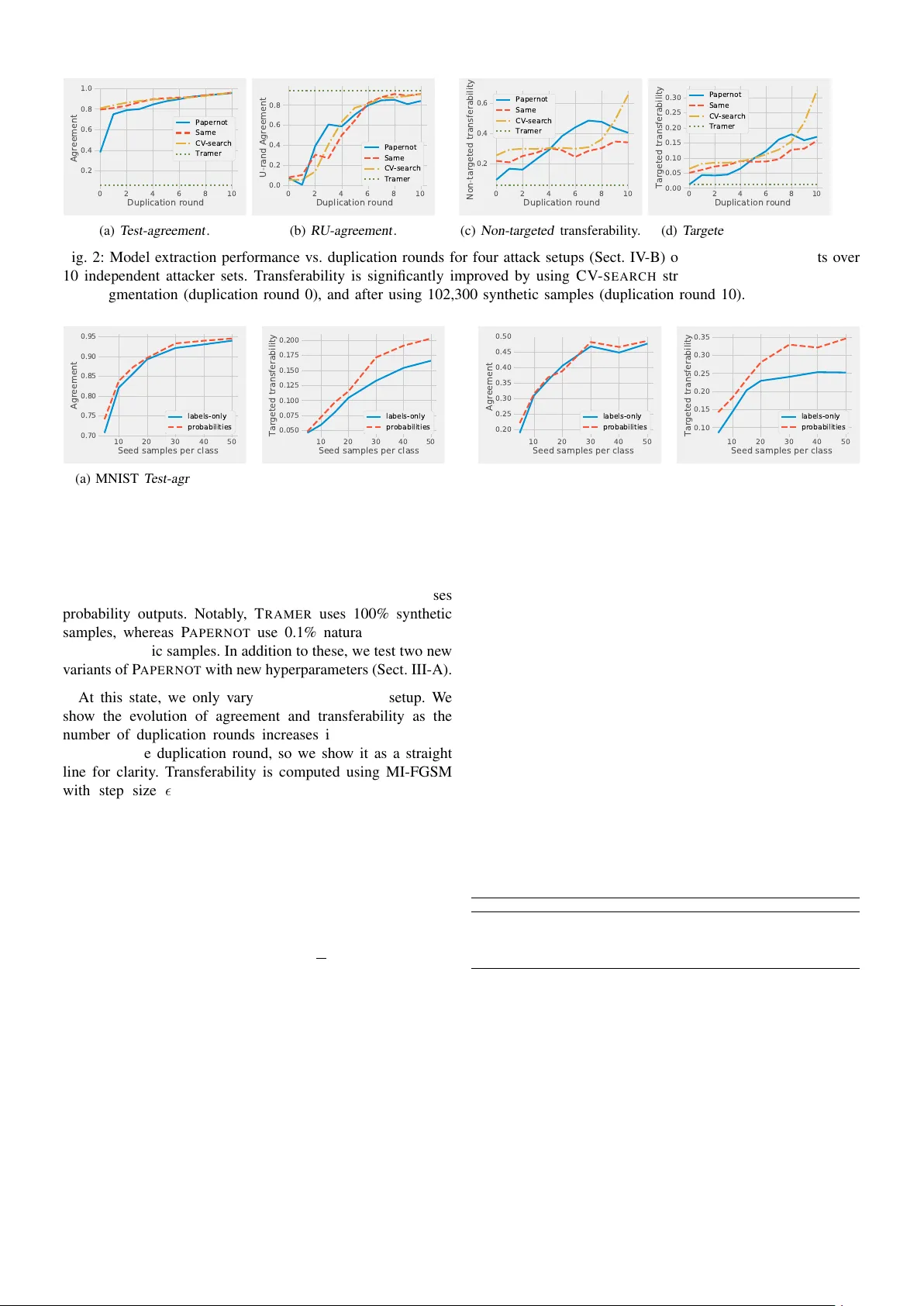
논문의 주요 내용은 크게 두 부분으로 구성된다. 첫 번째 부분은 **공격의 진화**이다. 저자들은 기존 모델 추출 공격(PAPERNOT, TRAMER)의 한계를 지적하며, 보다 효과적인 새로운 공격 프레임워크를 제안한다. 이 공격의 핵심은 1) **하이퍼파라미터 최적화**와 2) **향상된 합성 데이터 생성 기법**에 있다. 하이퍼파라미터 최적화는 공격자가 제한된 쿼리 데이터를 바탕으로 교차 검증을 수행하여 최적의 학습률, 에포크 수 등을 찾는 과정을 포함한다. 합성 데이터 생성에서는 PAPERNOT의 JbDA 기법을 넘어, FGSM, BIM, JSMA 등 다양한 적대적 예제 생성 알고리즘을 활용해 대체 모델의 결정 경계를 더 정밀하게 탐색하는 데이터를 생성한다. MNIST와 CIFAR-10 데이터셋에 대한 실험 결과, 이 새로운 공격은 기존 공격 대비 추출 모델의 예측 정확도를 최대 46%p, 적대적 예제 전이율을 최대 29-44%p 향상시켰다. 또한 실험을 통해 공격 성공의 핵심 요인으로 예측 확률값의 중요성, 모델 아키텍처 선택의 전략적 고려사항 등을 규명한다.
두 번째 부분은 **방어 기법 PRADA의 제안과 평가**이다. 모델 제공자 입장에서 공격자를 사전에 탐지하는 것은 매우 중요하다. PRADA는 '정상적인 API 사용 패턴'과 '모델 추출 공격 패턴'이 통계적으로 구분 가능하다는 가정에 기반한다. 구체적으로, 한 클라이언트가 시간 순으로 보낸 연속된 쿼리 벡터들 사이의 차이(δ)를 계산하고, 이 δ 값들의 분포가 정규 분포를 따른다는 정상 가설을 세운다. 모델 추출 공격 중에는 쿼리가 결정 경계 근처에 편향되어 생성되므로, 이 δ 분포가 정상 패턴과 유의미하게 달라진다. PRADA는 Kolmogorov-Smirnov 검정을 사용해 이 편차를 측정하고, 임계값을 초과할 경우 공격으로 판단한다. 평가 결과, PRADA는 PAPERNOT, TRAMER 공격 및 본 논문에서 제안한 새로운 공격을 모두 100%의 탐지율로 식별했으며, 정상 사용자 트래픽에서는 오탐을 발생시키지 않았다. 이는 실용적 환경에서 모델 추출 공격을 탐지하는 최초의 일반적(generic) 방법론으로 의의가 있다. 논문은 결론적으로 PRADA가 모델 보호를 위한 유용한 첫 걸음이지만, 공격자가 쿼리 패턴을 은닉하도록 진화할 경우 발생할 수 있는 향후 연구 과제에 대해서도 언급한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기