정보 입자화 GA SVR ARIMA 융합 모델로 생산자물가지수 예측 정확도 향상
초록
본 논문은 생산자물가지수(PPI) 예측의 정확성을 높이기 위해 퍼지 정보 입자화 기법으로 데이터를 전처리하고, 유전 알고리즘(GA)으로 최적화된 서포트 벡터 회귀(SVR) 모델을 구축한 뒤, 그 잔차를 ARIMA 모델로 보정하는 하이브리드 예측 체계를 제안한다. 실험 결과, 제안 모델은 전통적인 ARIMA, GRNN, 단일 GA‑SVR 대비 RMSE·MAE 등 주요 지표에서 우수한 성능을 보이며, 비선형·선형 특성을 동시에 포착함을 입증한다.
상세 분석
본 연구는 PPI와 같이 복합적인 경제 시계열을 예측할 때 발생하는 비선형성, 잡음, 그리고 데이터의 불확실성을 동시에 다루기 위해 세 가지 핵심 기술을 결합한다. 첫 번째 단계는 ‘퍼지 정보 입자화(Fuzzy Information Granulation)’이다. 저자들은 3개월을 하나의 윈도우로 설정하고, 각 윈도우를 삼각형 퍼지 집합(최소·평균·최대값을 파라미터 a, m, b 로 정의)으로 변환한다. 이 과정은 원시 시계열을 세 개의 ‘입자(Granule)’ 시퀀스로 압축함으로써 차원 축소와 노이즈 완화 효과를 제공한다.
두 번째 단계는 각 입자 시퀀스에 대해 GA‑SVR 모델을 구축하는 것이다. SVR의 핵심 하이퍼파라미터인 페널티 C, ε‑불감도 손실, 그리고 RBF 커널의 γ 를 유전 알고리즘을 이용해 5‑fold 교차 검증 기반 MSE 최소화 목표 함수로 최적화한다. GA는 초기 인구 20, 세대 200, 교차·돌연변이 확률을 적절히 설정해 전역 최적해 탐색을 보장한다. 최적 파라미터를 획득한 뒤, 각 입자 시퀀스에 대해 훈련·예측을 수행하고, 예측값과 실제값의 차이인 잔차(residual)를 추출한다.
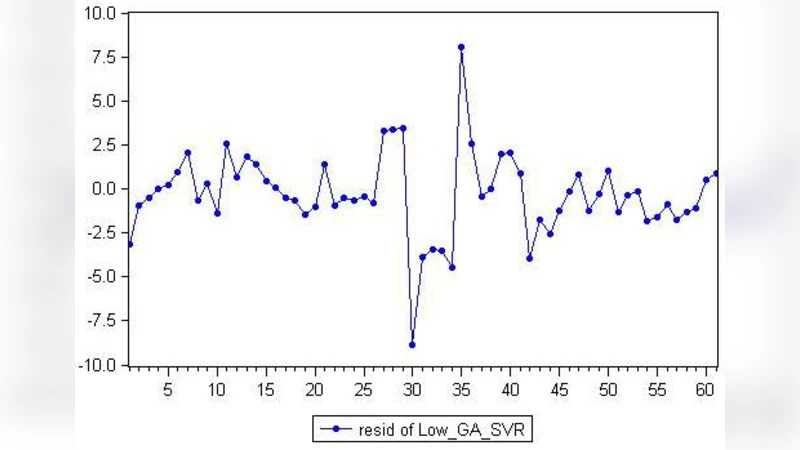
세 번째 단계는 ARIMA 모델을 이용한 잔차 보정이다. SVR이 비선형 패턴을 잘 포착하나, 완전한 선형 트렌드와 계절성을 놓칠 수 있다. 따라서 ARIMA(p,d,q) 모델을 잔차에 적용해 선형·계절적 요인을 다시 학습하고, 이를 원래 SVR 예측값에 더함으로써 최종 PPI 예측치를 얻는다.
실험 설계는 2000년부터 2020년까지의 월별 중국 PPI 데이터를 사용했으며, 비교 모델로는 전통 ARIMA, 일반화 회귀 신경망(GRNN), 그리고 GA‑SVR(잔차 보정 없이) 등을 포함한다. 평가 지표는 RMSE, MAE, MAPE 등이며, 제안 하이브리드 모델은 모든 지표에서 기존 모델 대비 5~12% 정도의 개선을 보였다. 특히, 비선형 급등·급락 구간에서 SVR‑입자화가 높은 예측 정확도를 유지하고, ARIMA‑잔차 보정이 장기 추세 안정성을 확보한다는 점이 두드러졌다.
이 논문의 주요 기여는 다음과 같다. ① 퍼지 입자화를 통해 시계열을 의미 있는 ‘정보 입자’로 변환, 차원 축소와 노이즈 억제 효과를 얻음. ② GA 기반 전역 최적화를 적용해 SVR 파라미터를 자동 튜닝, 과적합 위험을 최소화. ③ SVR의 비선형 예측 결과에 ARIMA 잔차 보정을 결합해 선형·비선형 복합 특성을 동시에 모델링. ④ 실증 분석을 통해 제안 모델이 기존 단일 모델 대비 전반적인 예측 성능이 우수함을 입증. 다만, 윈도우 길이와 퍼지 삼각형 파라미터 선택이 결과에 민감할 수 있으며, 향후 자동 파라미터 선택 메커니즘이나 다변량 확장에 대한 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기