하이브의 진화와 엔터프라이즈 데이터 웨어하우징
초록
Apache Hive는 초기 MapReduce 기반 배치 SQL 엔진에서 시작해, ACID 트랜잭션, Calcite 기반 옵티마이저, Tez·LLAP 런타임, 그리고 다중 데이터소스 연동 기능을 갖춘 엔터프라이즈급 데이터 웨어하우징 시스템으로 탈바꿈하였다. 논문은 이러한 네 가지 핵심 축(트랜잭션·SQL, 옵티마이저, 런타임, 연합)과 실험 평가를 통해 Hive의 현재 성능과 향후 로드맵을 제시한다.
상세 분석
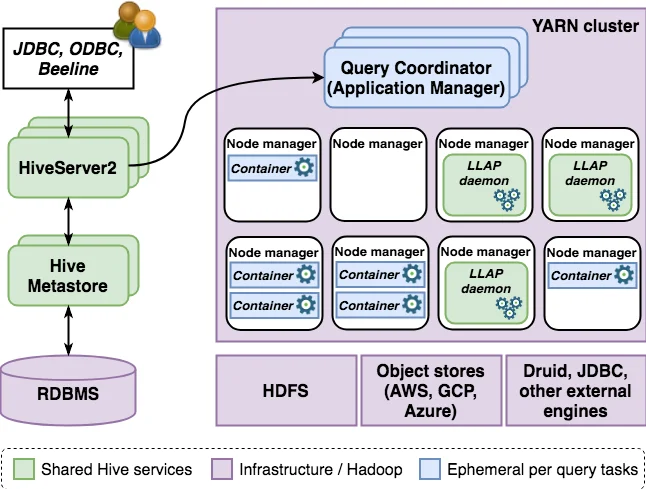
본 논문은 Hive가 전통적인 MPP(Data Warehouse) 기술과 클라우드·빅데이터 패러다임을 결합한 하이브리드 아키텍처로 재구성된 과정을 상세히 분석한다. 첫 번째 축인 SQL·ACID 지원에서는 Hive가 기본적인 ANSI‑SQL 구문을 넘어, 상관 서브쿼리, 윈도우 함수, GROUPING SETS, 무결성 제약조건 등을 구현했으며, Snapshot Isolation 기반의 ACID 트랜잭션을 메타스토어에 저장된 전역 TxnId와 테이블‑스코프 WriteId, FileId, RowId 체계로 관리한다. 쓰기 작업은 Base와 Delta 디렉터리 구조로 구분되며, Delete는 “삭제 레코드” 형태로 Delta에 기록된다. 컴팩션(마이너·메이저) 메커니즘은 파일 수와 디렉터리 수를 감소시켜 읽기 성능을 유지하고, 동시에 오래된 트랜잭션 정보를 정리한다. 두 번째 축인 옵티마이저는 자체 구현 대신 Apache Calcite을 통합함으로써 비용 기반 플래닝, 규칙 기반 리라이트, 물리적 연산자 선택 등을 활용한다. Hive는 쿼리 재옵티마이징, 결과 캐시, 물리적 뷰(Materialized View) 재작성 등을 추가해 MPP 수준의 최적화를 제공한다. 세 번째 축인 런타임은 기존 MapReduce에서 YARN‑호환 Tez로 전환하고, LLAP(Long‑Lived Process) 레이어를 도입해 지속적인 실행자 풀과 메모리 캐시를 제공한다. 이는 컨테이너 시작 오버헤드를 최소화하고, 벡터화된 연산과 컬럼형 저장 포맷(ORC, Parquet)과 결합해 인터랙티브 쿼리 지연 시간을 크게 낮춘다. 마지막 축인 연합(Federation)은 Calcite의 스토리지 핸들러와 플러그인 메커니즘을 활용해 Druid, HBase, 외부 클라우드 스토리지 등 다양한 백엔드에 대한 투명한 SQL 접근을 가능하게 한다. HiveServer2는 JDBC/ODBC 인터페이스를 제공하고, 쿼리 파이프라인은 파싱‑논리계획‑물리계획‑Task 컴파일‑YARN 제출 순으로 진행된다. 실험에서는 TPC‑DS, TPC‑HB와 같은 워크로드를 사용해 전통적인 Hive‑MR 대비 5~10배 이상의 성능 향상을 입증했으며, LLAP 캐시와 Tez DAG 최적화가 지연 시간 감소에 핵심 역할을 함을 보여준다. 전체적으로 논문은 Hive가 단순 배치 엔진을 넘어, 트랜잭션 보장, 고급 옵티마이저, 저지연 런타임, 그리고 멀티소스 연합을 갖춘 엔터프라이즈 데이터 웨어하우징 플랫폼으로 진화한 과정을 체계적으로 정리한다.
댓글 및 학술 토론
Loading comments...
의견 남기기