대규모 잡음 데이터에서 스위치 자동회귀 시스템 식별
본 논문은 측정 잡음이 큰 상황에서도 대량의 입출력 데이터를 활용해 스위치 자동회귀(SAR) 모델의 계수와 잡음 분포 파라미터를 추정하는 새로운 방법을 제시한다. 기대값 계산과 대수적 변환(Veronese 맵)을 이용해 행렬 Mₙ의 최소 특이값에 대응하는 특이벡터를 구함으로써 복잡도는 데이터 샘플 수에 의존하지 않는다. 실험을 통해 기존의 다항식·혼합정수 최적화 방식보다 훨씬 효율적임을 입증한다.
저자: Sarah Hojjatinia, Constantino M. Lagoa, Fabrizio Dabbene
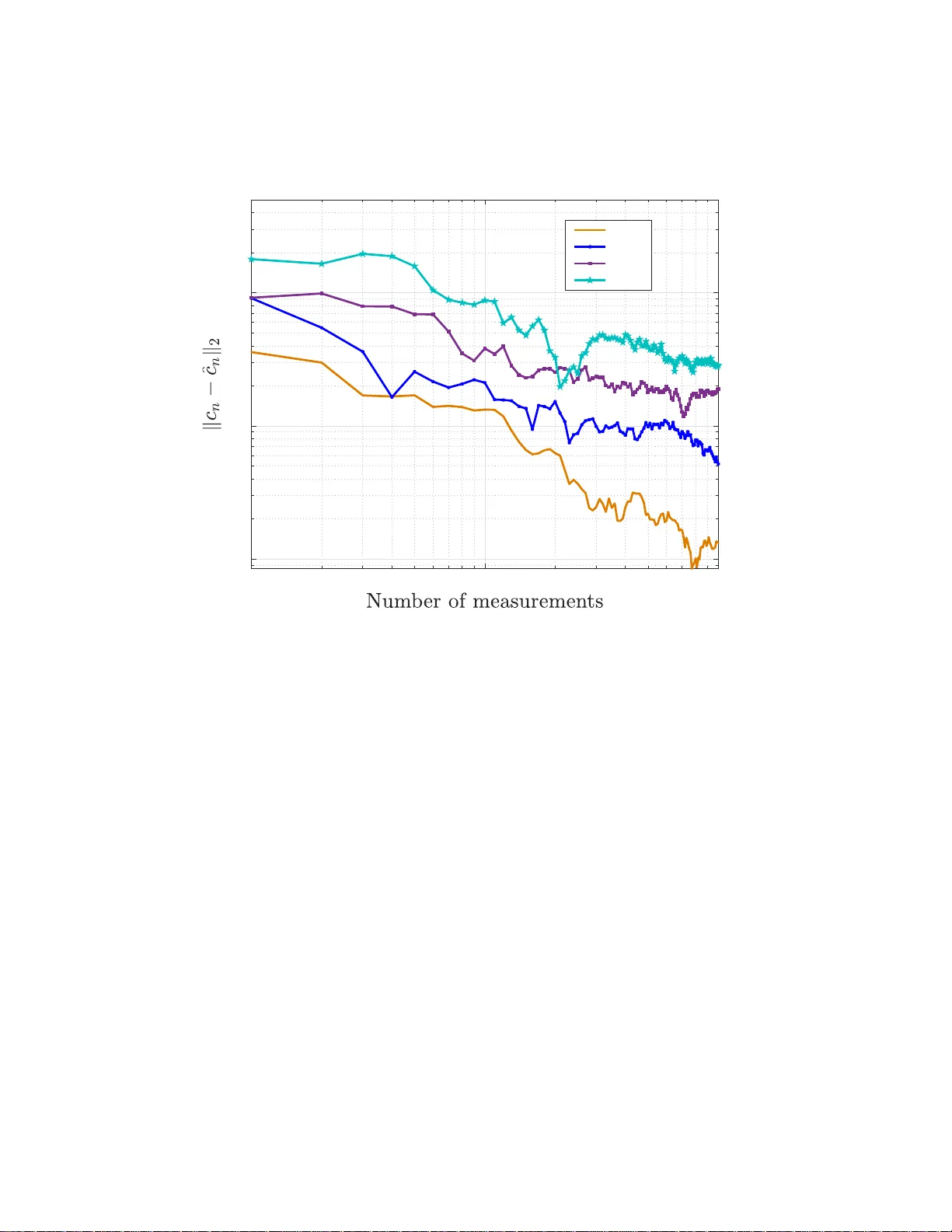
**1. 서론 및 연구 동기**
스위치(하이브리드) 시스템은 연속·이산 동적이 공존하는 복합 현상을 모델링하는 데 필수적이며, 자동차, 화학 공정, 바이오·통신 등 다양한 분야에 적용된다. 기존 연구는 소규모 데이터와 낮은 잡음 수준을 전제로 혼합정수·다항식 최적화 기법을 사용했지만, 데이터 양이 급증하고 잡음이 큰 실제 상황에서는 계산 복잡도가 급격히 증가한다. 특히 헬스케어 분야에서 활동 추적 장치가 생성하는 대용량 시계열은 이러한 문제를 직접적으로 드러낸다. 따라서 저자들은 ‘대규모·고노이즈’ 환경에서도 효율적으로 SAR 모델을 식별할 수 있는 방법을 모색한다.
**2. 관련 연구와 한계**
전통적인 방법은 (i) 다항식 기반 제약식에 대한 완전 탐색, (ii) 혼합정수 프로그래밍, (iii) 희소성·스파스성 가정 하의 볼록 최적화 등을 활용한다. 이들 접근법은 잡음이 작고 차원이 낮을 때는 성공적이지만, 샘플 수가 수천·수만에 달하거나 잡음 표준편차가 1 이상이면 메모리·시간 요구량이 비현실적으로 커진다. 최근의 Convex‑Relaxation 기반 기법도 여전히 대규모 행렬 연산을 필요로 한다.
**3. 문제 정의**
SAR 시스템은
xₖ = Σ_{j=1}^{n_a} a_{j}^{σ(k)} x_{k‑j} + Σ_{j=1}^{n_c} c_{j}^{σ(k)} u_{k‑j}
이며, 관측값은 yₖ = xₖ + ηₖ 로 주어진다. 여기서 σ(k)∈{1,…,n}은 활성 서브시스템, ηₖ는 독립·동일분포 잡음이며 파라미터 θ(예: 분산)만 알려져 있다. 목표는 입력 uₖ와 관측 yₖ만으로 a_{j}^{i}, c_{j}^{i} (i=1…n)와 θ를 동시에 추정하는 것이다.
**4. 무잡음 경우의 대수적 접근**
Regressor rₖ =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기