쌍둥이 인식을 위한 다중 바이오메트릭 시스템 음성·귀 기반 다중 모델
초록
본 논문은 쌍둥이 구별을 위해 귀 이미지와 음성 데이터를 결합한 다중 바이오메트릭 시스템을 제안한다. 손수 제작된 특징 추출기와 딥러닝 기반 모델을 각각 적용한 두 개의 알고리즘을 귀와 음성에 대해 별도로 운용하고, 점수 수준 융합을 통해 최종 인증 결과를 도출한다. 38쌍(76명)의 쌍둥이 데이터셋을 이용한 실험에서 Rank‑1 정확도 94.74%, Rank‑2 정확도 100%를 달성하였다.
상세 분석
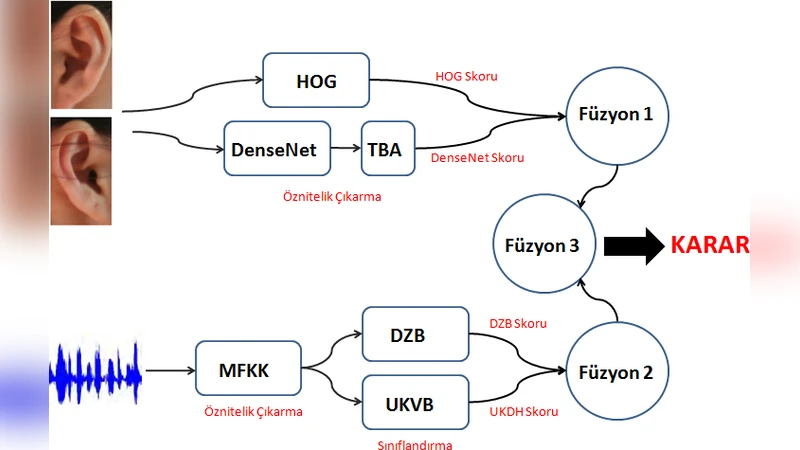
이 연구는 쌍둥이와 같이 생물학적 차이가 미미한 대상에 대한 식별 문제를 해결하기 위해 다중 모달리티와 다중 알고리즘을 동시에 활용한다는 점에서 의미가 크다. 먼저 귀 이미지에 대해서는 전통적인 HOG(Histogram of Oriented Gradients)와 최신 딥러닝 구조인 DenseNet을 적용하였다. DenseNet은 각 레이어가 이전 모든 레이어의 출력을 직접 연결함으로써 특징 재사용을 극대화하고, 파라미터 효율성을 높인다. 그러나 고차원 특징 벡터는 차원 축소가 필요했으며, 저자들은 TBA(Total Variance Analysis)라는 자체 구현 방법을 사용해 차원을 감소시켜 연산 부담을 완화하였다. HOG는 저차원이면서도 경계 정보를 잘 포착하지만, 실험 결과는 38.16%라는 낮은 인식률을 보였다. 반면, DenseNet+TBA 조합은 51.32%로 비교적 우수했다.
음성 인식에서는 MFCC(Mel Frequency Cepstral Coefficients)와 두 종류의 시계열 모델을 적용하였다. 첫 번째는 DTW(Dynamic Time Warping) 기반 분류기로, 시간축 변형을 정규화해 발화 속도 차이를 보정한다. 두 번째는 LSTM(Long Short-Term Memory) 기반의 UKVB(Unscented Kalman Variational Bayes) 모델로, 장기 의존성을 학습한다. MFCC+DTW 조합은 90.79%의 높은 정확도를 기록했으며, MFCC+UKVB는 61.84%에 그쳐 두 모델 간 성능 격차가 뚜렷했다. 이는 시계열 정렬 기반 DTW가 발화 변동성을 효과적으로 다루는 반면, LSTM 기반 모델이 데이터 양이 부족한 상황에서 과적합 위험이 있음을 시사한다.
점수 수준 융합 단계에서는 각 모달리티·알고리즘에서 얻은 매칭 점수를 tanh 정규화 후, 계층형(score-level) 융합 구조를 적용하였다. 먼저 귀와 음성 각각에 대해 다중 알고리즘 점수를 융합하고, 그 결과를 다시 두 모달리티 간에 융합한다. 가중치는 실험적으로 설정했으며, 귀보다 음성에 높은 가중치(0.85)를 부여해 전체 성능을 최적화했다. 최종 융합 결과 Rank‑1에서 94.74%, Rank‑2에서 100%의 정확도를 달성했으며, 이는 기존 단일 모달리티 혹은 단일 알고리즘 기반 시스템 대비 10% 이상 향상된 수치이다. 또한 ROC 곡선 아래 면적(AUC)도 99.97에 근접해 신뢰성을 입증한다.
데이터셋 규모가 작고 통제된 환경(각 인물당 3개의 음성 녹음, 좌·우 귀 이미지 각각 1장)이라는 제한점에도 불구하고, 다중 모달리티·다중 알고리즘·계층형 융합이라는 설계가 쌍둥이 구별 문제에 강력한 해결책이 될 수 있음을 보여준다. 향후 연구에서는 대규모 비통제 데이터와 추가적인 바이오메트릭(예: 얼굴, 지문)을 포함해 시스템의 일반화 능력을 검증할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기