실시간 합성 빅데이터 생성 프레임워크: 메모리·스토리지 절감 혁신
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 대규모 합성 데이터셋을 사전 생성·저장하는 전통적 방식의 메모리·디스크 부담을 해소하기 위해, 필요 시점에 배치 단위로 데이터를 생성하고, 생성에 사용된 파라미터만을 저장하는 “On‑the‑fly” 프레임워크를 제안한다. 배치 크기를 가용 RAM에 맞춰 조절함으로써 메모리 사용을 최소화하고, 전체 데이터셋을 재현할 수 있는 파라미터 기록 방식을 통해 저장 효율성을 크게 향상시킨다. 에너지 소비 시계열 데이터 예시와 복잡도 분석을 통해 프레임워크의 실용성을 입증한다.
상세 분석
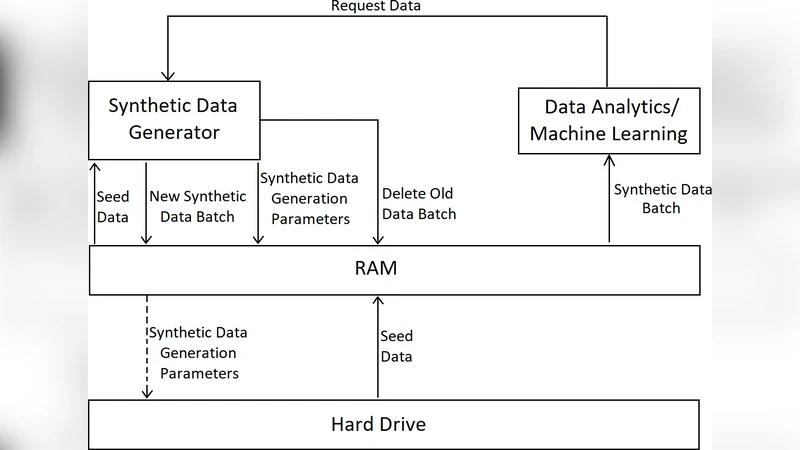
이 논문은 합성 데이터 생성 과정에서 발생하는 두 가지 주요 병목 현상—① 전체 데이터셋을 한 번에 생성하는 데 소요되는 CPU·시간 비용, ② 생성된 데이터를 디스크에 기록하고 다시 메모리로 로드하는 I/O 비용—을 동시에 해결하려는 시도로 평가할 수 있다. 기존 방식은 “Generate‑then‑Store” 패러다임을 따르며, 데이터 규모가 기하급수적으로 증가할 경우 RAM·디스크 용량이 급격히 소모된다. 저자들은 이를 “Generate‑on‑Demand” 형태로 전환함으로써, 데이터가 실제로 필요할 때만 생성하고 즉시 메모리 내에서 소비하도록 설계하였다.
핵심 아이디어는 파라미터 기반 재생성이다. 예시로 제시된 에너지 소비 시계열에서는 원시 시드 프로파일과 노이즈 프로파일을 각각 스케일링(λ₁, λ₂)하여 합성 데이터를 만든다. 전체 86,400개의 시계열 값 대신
댓글 및 학술 토론
Loading comments...
의견 남기기