소프트웨어 검증 속성, 어디서 찾을 것인가
초록
이 논문은 형식적 소프트웨어 검증의 핵심 과제인 ‘무엇을 검증할 것인가’에 초점을 맞춥니다. 검증할 속성(φ)이 당연히 주어진다고 가정하는 기존 접근법을 넘어, ‘고수준 원칙(테넷)‘에서 출발해 도메인 지식과 시스템 설계를 활용해 구체적인 검증 속성을 체계적으로 도출하는 프로세스를 제안합니다.
상세 분석
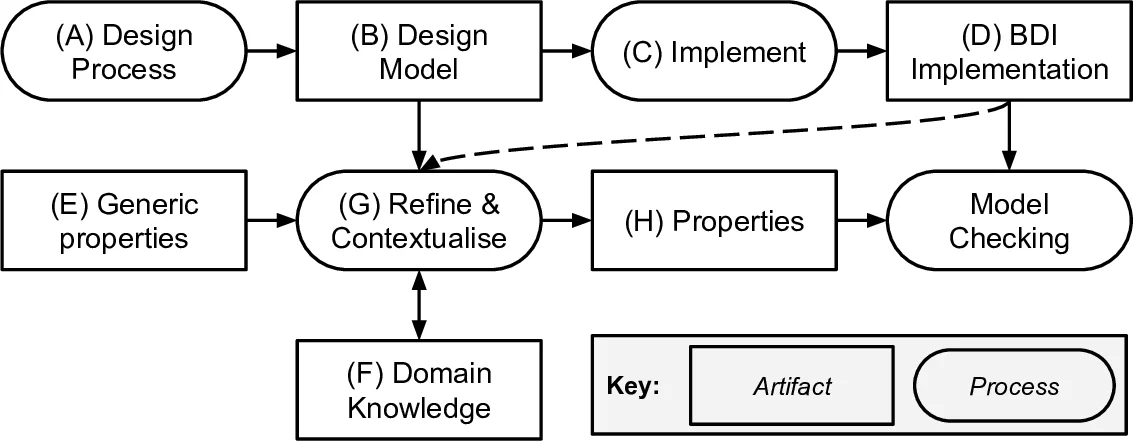
이 논문은 형식적 방법론 연구에서 종종 간과되는 근본적인 문제, 즉 “검증할 속성 자체를 어떻게 정의할 것인가"를 정면으로 다룹니다. 저자는 이 문제를 해결하기 위해 ‘상향식(Bottom-up)‘이 아닌 ‘하향식(Top-down)’ 접근법을 제시하는데, 이는 실용적이며 실제 시스템 개발 프로세스에 자연스럽게 통합될 수 있는 장점이 있습니다.
핵심 방법론은 비공식적인 고수준 원칙(예: “인간에게 해를 끼치지 말라”)을 출발점으로 삼고, 구체적인 도메인 지식(논리적 함의로 표현)과 시스템의 목표 트리 설계를 단계적으로 적용하여 공식적인 LTL 속성으로 정제해 나가는 ‘정제 트리’ 구축 과정입니다. 여기서 중요한 통찰은, 검증 속성 도출이 단순한 번역이 아닌, 도메인 지식과 시스템 설계에 대한 깊은 이해와 분석을 요구하는 창의적인 엔지니어링 활동이라는 점입니다.
논문은 van Lamsweerde와 Letier의 ‘장애물(Obstacle) 도출’ 기법과 유사성을 인정하면서도 차별점을 분명히 합니다. 기존 기법이 이미 정형화된 시스템 목표에서 장애물을 찾는 데 중점을 둔다면, 본 논문의 접근법은 검증의 궁극적 목적인 ‘테넷’ 보존에서 시작해, 해당 테넷을 위반할 수 있는 모든 구체적인 시스템 행위를 역으로 추적합니다. 이는 보다 근본적인 안전/안전성 속성에 초점을 맞추게 합니다.
한계점으로는, 정제 과정의 각 단계에서 올바른 도메인 지식 규칙을 선택하고 적용하는 데 인간의 판단이 여전히 크게 개입해야 하며, 이 과정을 완전히 자동화하기는 어렵다는 점을 지적할 수 있습니다. 또한, 확률적 요소가 중요한 도메인(예: 리마인더가 실제 행동을 보장하지 않는 경우)을 정확히 모델링하기 위해서는 명제 논리나 LTL을 넘어선 richer한 표현력이 필요함을 인정하고 있습니다. 그럼에도 불구하고, 이 프레임워크는 검증 속성 도출이라는 불완전한 예술을 체계적인 공학적 실천으로 발전시키는 중요한 초기 청사진을 제시합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기