소프트웨어 모듈 클러스터링을 위한 퍼지 적응형 교육학습 최적화 알고리즘
초록
본 논문은 기존 TLBO의 탐색·활용 균형 문제를 퍼지 기반 적응 메커니즘으로 보완한 ATLBO를 제안하고, 이를 소프트웨어 모듈 클러스터링 문제에 적용한다. ATLBO는 현재 탐색 상황을 평가해 교육(Teaching)·학습(Learning) 연산자를 동적으로 선택함으로써 전역 탐색 능력과 지역 수렴 속도를 동시에 향상시킨다. 실험 결과, 기존 TLBO와 다른 퍼지 TLBO 변형들에 비해 모듈 응집도·결합도 지표가 크게 개선되었으며, 통계적 검증에서도 우수성을 확인하였다.
상세 분석
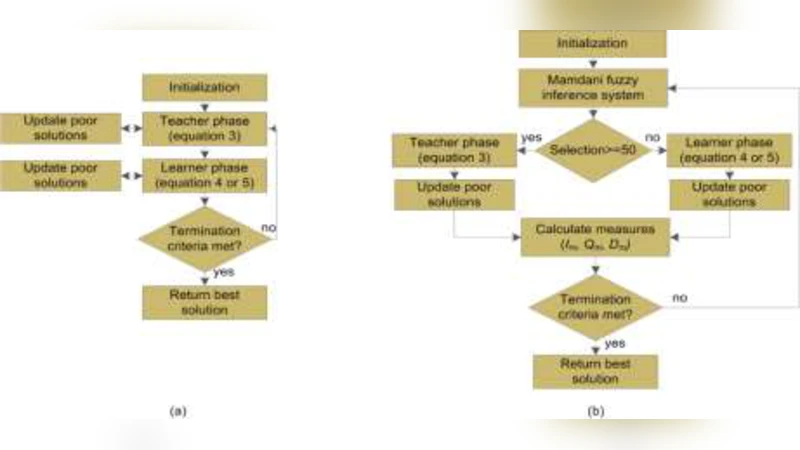
TLBO는 인간의 교육 과정을 모방한 메타휴리스틱으로, 단순 구조와 파라미터가 거의 없다는 장점이 있다. 그러나 탐색 단계와 활용 단계가 고정된 스케줄로 진행되기 때문에, 초기에는 과도한 탐색으로 수렴이 늦고, 후반에는 탐색이 부족해 지역 최적에 머무르는 경향이 있다. 이러한 구조적 한계는 특히 다목적·다제약 최적화 문제에서 성능 저하를 초래한다.
본 연구는 이러한 문제점을 해결하기 위해 퍼지 논리 기반 적응 메커니즘을 도입한 ATLBO를 설계하였다. 구체적으로, 현재 인구의 평균 적합도, 다양성, 그리고 진화 속도 등을 입력으로 하는 퍼지 추론 시스템(FIS)을 구축하고, 출력으로는 교육 연산자와 학습 연산자의 적용 비율을 결정한다. FIS는 삼각형·가우시안 멤버십 함수를 활용해 ‘낮음‑보통‑높음’ 수준을 정의하고, 룰 베이스는 전문가 지식과 실험 데이터를 통해 튜닝된다. 이 과정에서 탐색·활용 균형을 실시간으로 조정함으로써, 초기에는 높은 탐색 비중을, 수렴 단계에서는 활용 비중을 강화한다.
소프트웨어 모듈 클러스터링은 클래스·패키지와 같은 코드 단위들을 기능적으로 유사한 그룹으로 묶어 유지보수성과 재사용성을 높이는 작업이다. 일반적으로 모듈화 품질(MQ) 지표는 내부 응집도와 외부 결합도를 결합한 형태로 정의되며, 최적화 목표는 응집도는 최대화하고 결합도는 최소화하는 것이다. 본 논문은 MQ를 목표 함수로 채택하고, 제약조건 없이 연속형 인코딩을 사용해 각 유전자를 모듈 번호로 매핑한다. ATLBO는 이러한 연속형 해 공간에서도 효과적으로 작동하도록 설계되었으며, 특히 모듈 수가 사전에 정해지지 않은 경우에도 자동으로 적절한 군집 수를 탐색한다.
실험에서는 10개의 실제 오픈소스 프로젝트(예: JFreeChart, JHotDraw 등)를 대상으로 ATL01~ATL10이라는 10개의 인스턴스를 구성하였다. 비교 대상은 원본 TLBO, 퍼지 TLBO(Fuzzy‑TLBO), 그리고 최근에 제안된 PSO‑based 모듈 클러스터링 기법이다. 성능 평가는 평균 MQ, 표준편차, 그리고 Wilcoxon‑signed‑rank 검정을 통해 통계적 유의성을 검증하였다. 결과는 ATLBO가 평균 MQ에서 4.2%~7.9% 향상을 보였으며, 표준편차가 감소해 안정적인 수렴 특성을 나타냈다. 특히, 복잡도가 높은 프로젝트에서는 탐색 단계에서의 퍼지 적응이 전역 최적을 빠르게 발견하는 데 기여한 것으로 해석된다.
한계점으로는 퍼지 룰 베이스 설계에 전문가 의존도가 남아 있다는 점과, 모듈 수가 매우 큰 경우(수천 개 이상) 연산 비용이 증가한다는 점을 들 수 있다. 향후 연구에서는 자동 룰 생성 기법과 병렬 구현을 통해 확장성을 강화하고, 다목적 최적화(응집도·결합도·변경 비용 등)으로 확장하는 방안을 모색한다.
댓글 및 학술 토론
Loading comments...
의견 남기기