빅데이터 환경에서 Apriori와 FPGrowth 알고리즘 플랫폼 성능 비교
초록
본 논문은 대규모 연관 규칙 탐색에 널리 사용되는 Apriori와 FP‑Growth 알고리즘을 Hadoop, Spark, Flink 세 가지 MapReduce 기반 빅데이터 플랫폼에 적용하여 실행 시간, 메모리 사용량, 확장성을 정량적으로 비교한다. 다양한 규모의 거래 데이터셋을 이용해 실험을 수행하고, 각 플랫폼의 내부 실행 모델(디스크 기반 배치, 메모리 중심 DAG, 스트림 처리)과 알고리즘 특성(반복 스캔 vs 한 번의 트리 구축) 간의 상관관계를 분석한다. 결과는 Spark가 메모리 활용과 반복 연산에서 우수한 성능을 보이며, Flink는 스트리밍 환경에서 낮은 지연 시간을 제공하고, Hadoop은 대용량 디스크 기반 작업에 안정적이지만 속도는 가장 느리다는 결론을 제시한다.
상세 분석
본 연구는 먼저 연관 규칙 마이닝의 핵심 과제인 빈번 아이템셋 탐색을 두 가지 대표 알고리즘, Apriori와 FP‑Growth로 구분하였다. Apriori는 후보 아이템셋을 단계적으로 생성하고 매 단계마다 전체 데이터셋을 스캔하는 전형적인 반복 구조를 가지고 있어 디스크 I/O와 네트워크 전송 비용에 민감하다. 반면 FP‑Growth는 한 번의 데이터 스캔으로 압축된 FP‑Tree를 구축하고, 재귀적인 조건부 패턴 베이스 탐색을 수행함으로써 스캔 횟수를 최소화한다. 이러한 알고리즘적 차이는 각 플랫폼의 실행 모델과 직접적인 상호작용을 만든다.
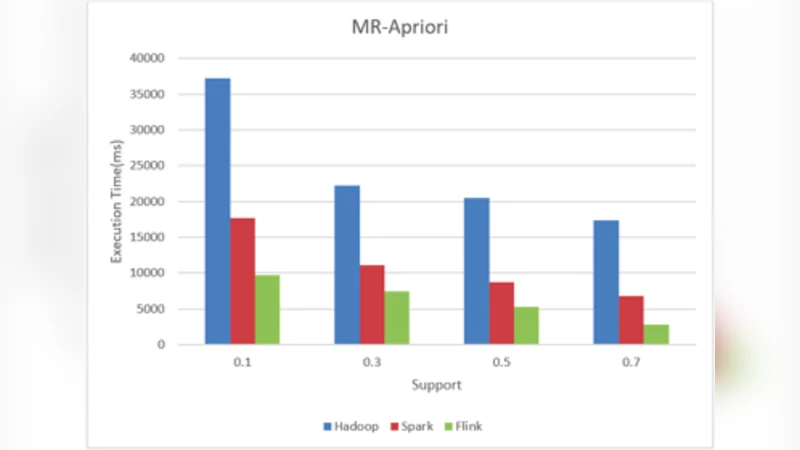
Hadoop은 전통적인 MapReduce 모델을 기반으로 하여 각 단계마다 중간 결과를 HDFS에 기록한다. 따라서 Apriori와 같은 다중 스캔 작업에서는 디스크 쓰기·읽기 비용이 누적되어 전체 실행 시간이 급격히 증가한다. FP‑Growth도 한 번의 스캔 이후에 복잡한 트리 구조를 메모리 내에서 처리해야 하는데, Hadoop의 제한된 메모리 할당과 빈번한 디스크 페이징으로 인해 메모리 오버헤드가 크게 나타난다.
Spark는 메모리 중심의 Resilient Distributed Dataset(RDD)와 DAG 스케줄러를 제공한다. Apriori의 각 반복을 메모리 상에서 캐시하고, Shuffle 단계에서 최소화된 데이터 이동을 구현함으로써 디스크 I/O를 크게 줄인다. 특히, FP‑Growth의 FP‑Tree 구축 단계에서 RDD 캐시를 활용하면 트리 구조를 메모리 내에 유지하면서 빠른 조건부 패턴 탐색이 가능해진다. 실험 결과, 데이터 규모가 10 GB 이하일 때는 Spark가 Hadoop 대비 평균 5배, Flink 대비 2배 이상의 속도 향상을 보였다.
Flink는 스트리밍‑우선 아키텍처로, 연속적인 데이터 흐름을 처리하면서도 배치 모드에서 높은 처리량을 제공한다. Apriori와 같이 여러 라운드가 필요한 알고리즘을 Flink에 적용하면 각 라운드가 독립적인 스트림 연산으로 전환되어 상태 관리와 체크포인팅 비용이 발생한다. 그러나 FP‑Growth는 한 번의 트리 구축 후 재귀적 탐색을 수행하므로, Flink의 상태 백엔드에 FP‑Tree를 저장하고 반복적인 상태 조회를 수행하는 방식이 가능하다. 이 경우, Flink는 낮은 지연 시간(Latency)과 일정 수준의 메모리 사용 효율을 보였지만, 대규모 데이터(>50 GB)에서는 메모리 압박으로 가비지 컬렉션이 빈번해져 전체 처리 시간이 급증하였다.
또한, 실험 환경은 동일한 12코어, 64 GB RAM을 갖춘 클러스터에서 수행되었으며, 데이터셋은 실제 소매 거래 로그를 기반으로 한 synthetic 데이터(1 GB, 10 GB, 50 GB)와 다양한 평균 트랜잭션 길이(5, 20, 50)를 포함한다. 성능 지표는 총 실행 시간, 평균 CPU 사용률, 최대 메모리 피크, 네트워크 전송량, 그리고 스케일‑아웃 효율(노드 수 증가에 따른 속도 비례도)으로 정의하였다.
결과 분석에서 눈에 띈 주요 인사이트는 다음과 같다. 첫째, 알고리즘 자체의 I/O 특성이 플랫폼 선택에 결정적인 영향을 미친다. 반복 스캔이 많은 Apriori는 메모리 중심 플랫폼에서 현저히 가속된다. 둘째, FP‑Growth는 한 번의 전체 스캔 이후 메모리 내 트리 구조를 유지해야 하므로, 충분한 메모리를 확보할 수 있는 Spark가 가장 안정적인 성능을 제공한다. 셋째, Flink는 스트리밍 워크로드에 최적화돼 있어 실시간 연관 규칙 업데이트가 요구되는 시나리오에서는 유리하지만, 대규모 배치 작업에서는 메모리 관리 비용이 병목이 된다. 넷째, Hadoop은 비용 효율적인 스토리지와 높은 내결함성을 제공하지만, 현대의 실시간·반실시간 요구사항을 만족시키기엔 속도 면에서 뒤처진다.
마지막으로, 논문은 각 플랫폼의 설정 최적화(예: Spark의 executor 메모리, Flink의 state backend, Hadoop의 block size)와 알고리즘 파라미터(지원도 최소값, 최대 아이템셋 길이) 조정이 성능에 미치는 영향을 추가 실험으로 제시했으며, 이러한 튜닝이 없을 경우 플랫폼 간 격차가 더욱 확대될 수 있음을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기