엔드투엔드 음성합성의 숨은 문맥 특징 분석
본 논문은 엔드투엔드 TTS 모델의 인코더 출력이 전통적인 파라메트릭 TTS에서 사용되는 8가지 핵심 문맥 특징을 얼마나 잘 내포하고 있는지 정량적으로 평가한다. 최신 신경망 기반 평가 방법을 적용해 음소, 음절, 단어 수준의 음운·언어·운율 정보를 분류 실험으로 검증했으며, 인코더가 음소 정체성, 모음 약화, 어휘 강세, 품사 등 다양한 문맥 정보를 효과적으로 학습한다는 결과를 제시한다.
저자: Kohki Mametani, Tsuneo Kato, Seiichi Yamamoto
본 논문은 엔드투엔드 텍스트‑투‑스피치(End‑to‑End TTS) 시스템이 텍스트 입력으로부터 어떤 문맥 정보를 추출하고, 이를 음성 합성에 어떻게 활용하는지를 정량적으로 분석한다. 기존의 통계적 파라메트릭 음성 합성(Statistical Parametric Speech Synthesis, SPSS)에서는 텍스트 전처리 단계에서 687차원에 달하는 고차원 컨텍스트 피처(l)를 수동으로 설계하고, 이를 HMM·DNN·LSTM 기반의 음향 모델에 입력하였다. 반면, 최신 엔드투엔드 TTS는 텍스트‑음향 매핑을 하나의 신경망으로 통합해, 별도의 피처 엔지니어링 없이 자동으로 컨텍스트를 학습한다. 그러나 이러한 자동 학습 과정이 실제로 어떤 언어·음운·운율 정보를 내포하고 있는지는 아직 명확히 밝혀지지 않았다.
저자는 먼저 두 모델 간의 구조적 유사성을 제시한다. 파라메트릭 TTS에서 텍스트는 l이라는 고차원 벡터로 변환돼 음향 모델에 공급되고, 엔드투엔드 TTS에서는 인코더 출력 h가 동일한 역할을 수행한다는 점이다. 이를 바탕으로, 파라메트릭 TTS에서 널리 사용되는 26개의 표준 컨텍스트 피처 중 실제 음성 품질에 가장 큰 영향을 미치는 8가지를 선정하였다(표 1). 선정 기준은 기존 연구에서 강조된 음소 정체성(전·현·후), 음절 내 위치, 어휘 강세, 현재 음절의 모음 종류, 그리고 품사 등이다.
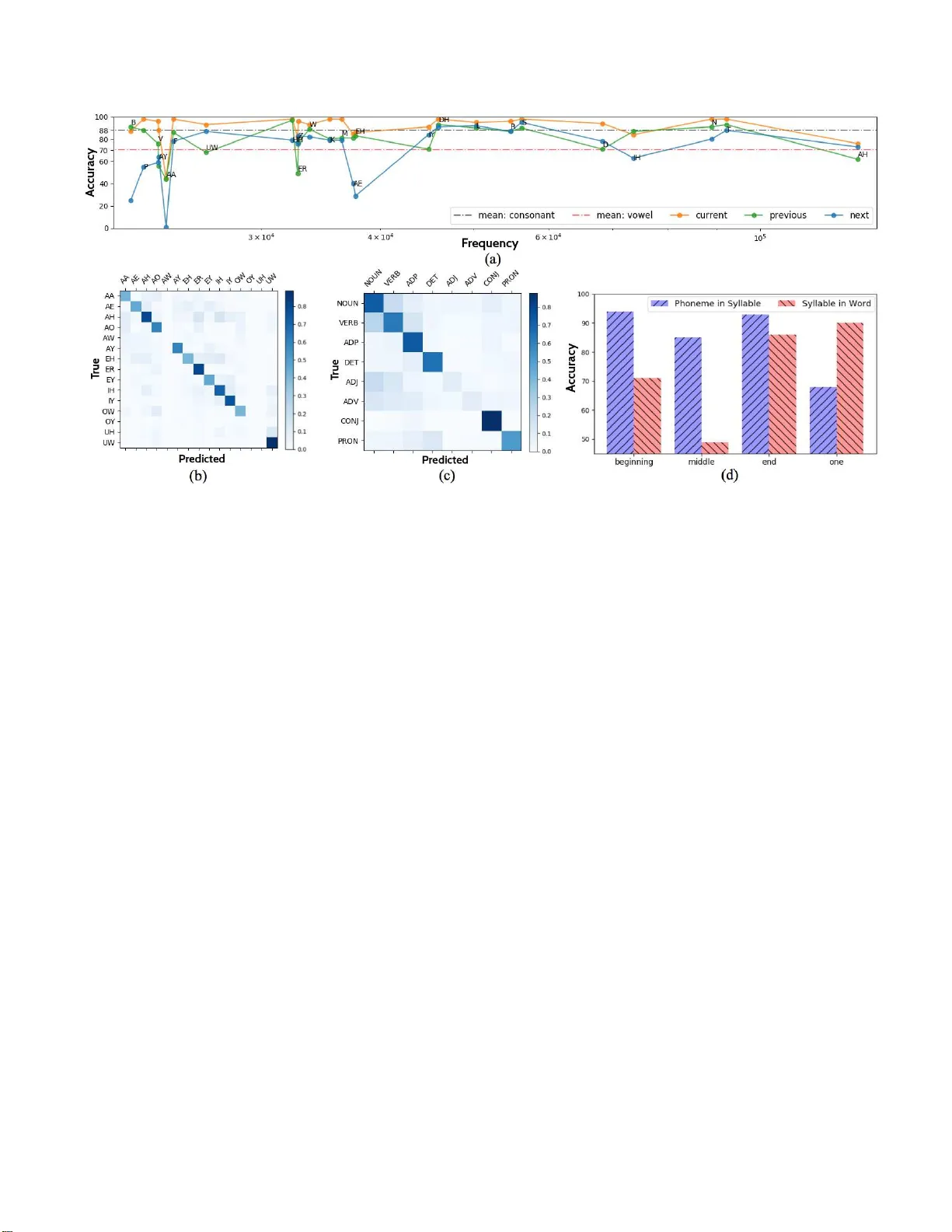
평가 방법은 최근 제안된 ‘내부 표현 정량 분석’ 절차를 차용한다. 구체적으로, Baidu Deep Voice 3 기반의 엔드투엔드 TTS 모델을 LJ Speech 데이터셋(13,100쌍)으로 학습시킨 뒤, M‑AILABS 데이터셋에서 25,000개의 영어 문장을 사용해 인코더 출력(h)을 추출한다. 각 출력에 대해 위 8가지 컨텍스트 라벨을 부여하고, 128‑차원 입력을 받는 단순 피드포워드 신경망(숨은 층 64노드)으로 분류기를 학습시킨다. 분류 정확도는 해당 컨텍스트가 인코더에 얼마나 잘 내재되어 있는지를 나타내는 프록시 지표로 활용된다.
실험 결과는 다음과 같다.
1. **음소 정체성**: 현재 음소를 구분하는 정확도는 84.0 %로 가장 높았으며, 이전 음소와 다음 음소는 각각 73.1 %와 67.1 %를 기록했다. 이는 인코더가 현재 심볼의 음운 정보를 가장 잘 포착한다는 것을 의미한다.
2. **모음 약화**: 모음에 대한 정확도가 70.7 %에 불과해, 자음(88.1 %)에 비해 현저히 낮았다. 이는 실제 발화에서 모음이 약화되는 현상이 인코더 표현에도 반영된 결과로 해석된다.
3. **음절 수준 강세**: 어휘 강세를 판별한 정확도는 86.3 %로, 강세 정보가 인코더에 강하게 내재됨을 보여준다. 다만, 강세와 prosodic stress가 혼동될 가능성도 제시되었다.
4. **음절 내 모음 종류**: 현재 음절의 모음 종류를 구분한 정확도는 63.8 %에 그쳤다. 이는 모음 약화와 연관된 어려움이며, 드물게 등장하는 모음(AW, OY, UH)에서 오류가 집중되었다.
5. **품사(POS) 태깅**: 8가지 대분류 품사 중 명사·동사·형용사·부사의 구분이 가장 어려웠으며, 전체 정확도는 약 70 % 수준이었다. 표면 형태가 유사한 단어들 간의 혼동이 주요 원인으로 분석되었다.
이러한 결과는 엔드투엔드 TTS가 전통적인 파라메트릭 시스템에서 사용되던 풍부한 문맥 정보를 자동으로 학습한다는 것을 실증한다. 특히, 음성 신호의 물리적 제약(예: 모음 약화)이 인코더 출력에 반영되어, 기존에 명시적으로 설계해야 했던 음운·운율 특징을 신경망이 자체적으로 포착한다는 점이 주목할 만하다. 이는 향후 TTS 연구에서 복잡한 피처 엔지니어링을 최소화하고, 데이터 기반으로 보다 정교한 언어‑음향 상관관계를 모델링할 수 있는 가능성을 열어준다. 또한, 제안된 정량 평가 프레임워크는 다른 엔드투엔드 음성·언어 모델의 내부 표현을 비교·분석하는 데도 활용될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기