음성 문장 임베딩을 통한 다중모달 이해
본 논문은 음성 신호를 입력으로 받아 음향 정보와 언어 정보를 동시에 보존하는 문장 수준 임베딩을 학습한다. Temporal Convolutional Network(TCN) 기반 인코더와 두 개의 디코더(음향 재구성, 텍스트 복원)를 활용한 멀티태스크 학습으로, 얻어진 임베딩은 자동 음성 인식과 감정 인식에서 기존 음소·단어 임베딩을 능가한다.
저자: Albert Haque, Michelle Guo, Prateek Verma
본 논문은 음성 신호를 입력으로 받아 음향적 특성과 언어적 의미를 동시에 보존하는 문장 수준 임베딩을 학습하는 새로운 프레임워크를 제시한다. 기존 연구들은 문자, 음소, 혹은 단어 수준의 임베딩에 머물러 있어, 긴 문맥을 필요로 하는 고차원 인지 작업(예: 감정 인식, 억양 분석)에서 한계를 보였다. 이를 극복하고자 저자들은 두 가지 핵심 기술을 결합하였다. 첫 번째는 Temporal Convolutional Network(TCN)를 기반으로 한 인코더이다. TCN은 인과적 컨볼루션과 지수적 dilation을 활용해 수천 프레임에 이르는 입력을 한 번에 처리하면서도 장기 의존성을 효과적으로 학습한다. 이는 RNN 기반 모델이 겪는 학습 불안정성(기울기 소실·폭발)과 병렬 연산의 비효율성을 피한다. 두 번째는 멀티태스크 학습이다. 인코더가 출력한 고정 차원 벡터를 두 개의 디코더에 전달한다. 하나는 원본 mel‑spectrogram을 재구성하도록 설계돼 음향 정보를 보존하고, 다른 하나는 텍스트 전사(문자열)를 복원하도록 하여 언어 정보를 압축한다. 두 디코더의 손실을 가중합(L_total = λ₁·L_acoustic + λ₂·L_linguistic)으로 결합함으로써, 인코더 파라미터가 음향과 언어 양쪽 목표를 동시에 최적화하도록 만든다. 이와 같은 하드 파라미터 공유 방식은 임베딩이 “오디오‑언어 복합 표현”이 되게 만든다.
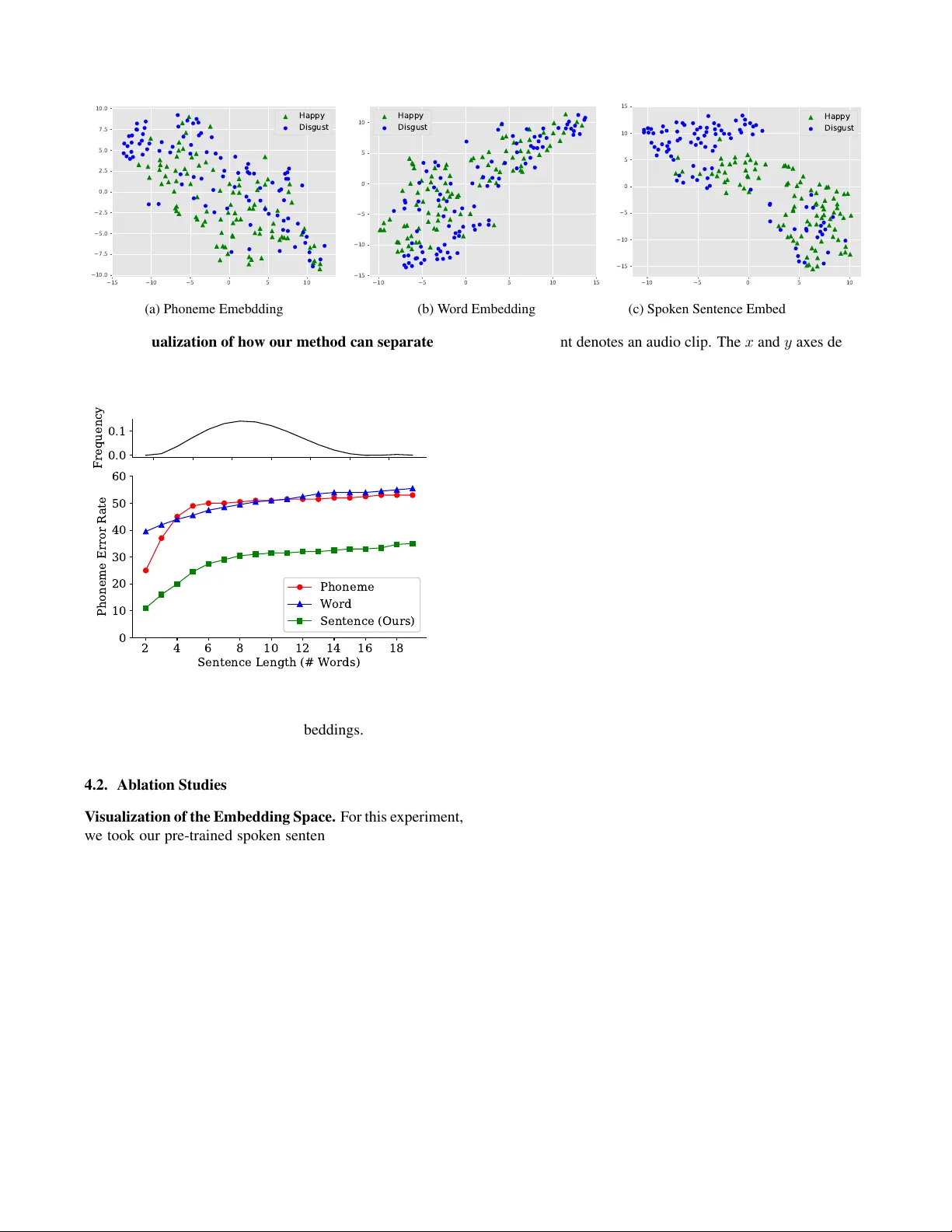
학습 데이터로는 460시간 규모의 LibriSpeech를 사용했으며, 사전 학습된 인코더를 고정한 뒤 두 개의 다운스트림 작업에 적용했다. 첫 번째는 TIMIT 데이터셋을 이용한 자동 음성 인식(ASR)이며, 두 번째는 RAVDESS 데이터셋을 이용한 감정 인식이다. 비교 대상은 기존의 음소·단어 임베딩과 두 가지 융합 방법(Uniform Average와 Deep Averaging Network)이다. 실험 결과, 제안된 문장 임베딩은 PER(음소 오류율)과 WER(단어 오류율) 모두에서 기존 방법을 크게 앞섰다. 특히, 음소 수준 임베딩은 WER이 70% 이상으로 낮은 성능을 보였던 반면, 문장 임베딩은 10% 이하의 WER을 기록했다. 감정 인식에서도 정확도, 정밀도, 재현율 모두 최고 수준을 달성했으며, t‑SNE 시각화에서는 감정 라벨이 명확히 군집되는 것을 확인했다.
추가 분석에서는 문장 길이에 따른 성능 변화를 조사했다. 일반적으로 문장이 길어질수록 고정 차원 임베딩의 압축 한계로 인해 오류율이 상승하지만, 제안 방법은 다른 임베딩에 비해 상승 폭이 작았다. 이는 TCN 인코더가 긴 시퀀스에서도 충분히 풍부한 정보를 압축한다는 증거이다. 또한, Deep Averaging Network보다 단순 평균이 비슷한 성능을 보인 점은 인코더 자체가 이미 강력한 표현을 학습하고 있음을 의미한다.
관련 연구와 비교했을 때, 텍스트 기반 Universal Sentence Encoder(USE)는 중간 단계(단어 임베딩)를 평균하거나 어텐션을 적용해 문장을 벡터화한다. 반면 본 방법은 음성 신호에서 직접 문장 수준 벡터를 학습함으로써, 음향적 변동(피치, 억양)과 언어적 의미를 동시에 포착한다. 이는 특히 감정 인식과 같은 음향-언어 복합 특성이 중요한 작업에 유리하다.
결론적으로, 이 논문은 멀티모달(음향·언어) 문장 임베딩을 학습하는 실용적인 프레임워크를 제시하고, 이를 통해 ASR과 감정 인식에서 기존 수준을 뛰어넘는 성능을 입증했다. 향후 연구는 (1) 가변 길이 임베딩을 도입해 매우 긴 입력(예: 전체 곡, 다중 문장)에도 적용 가능하도록 확장, (2) 다른 음성·음악 도메인(예: 노래 가사와 멜로디)으로 전이 학습을 시도, (3) 외부 언어 모델 없이도 문맥 정보를 충분히 활용할 수 있는 완전한 엔드‑투‑엔드 스피치 이해 시스템 구축 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기