주의 기반 CNN BLSTM을 활용한 발화 수준 종단형 언어 식별
초록
본 논문은 가변 길이의 음성 발화를 직접 입력으로 받아 발화 수준의 언어 식별을 수행하는 엔드‑투‑엔드 모델을 제안한다. CNN‑BLSTM 구조로 지역 패턴을 추출하고, 자기‑주의 기반 풀링(SAP) 층을 통해 고정 차원의 발화 표현을 만든 뒤, 최종 전결층에서 언어를 분류한다. NIST LRE07 폐쇄형 과제에서 3 초, 10 초, 30 초 길이의 테스트에 대해 기존 CNN‑TAP·CNN‑SAP 대비 오류율을 크게 낮추었으며, 시스템 융합까지 적용해 추가 성능 향상을 확인하였다.
상세 분석
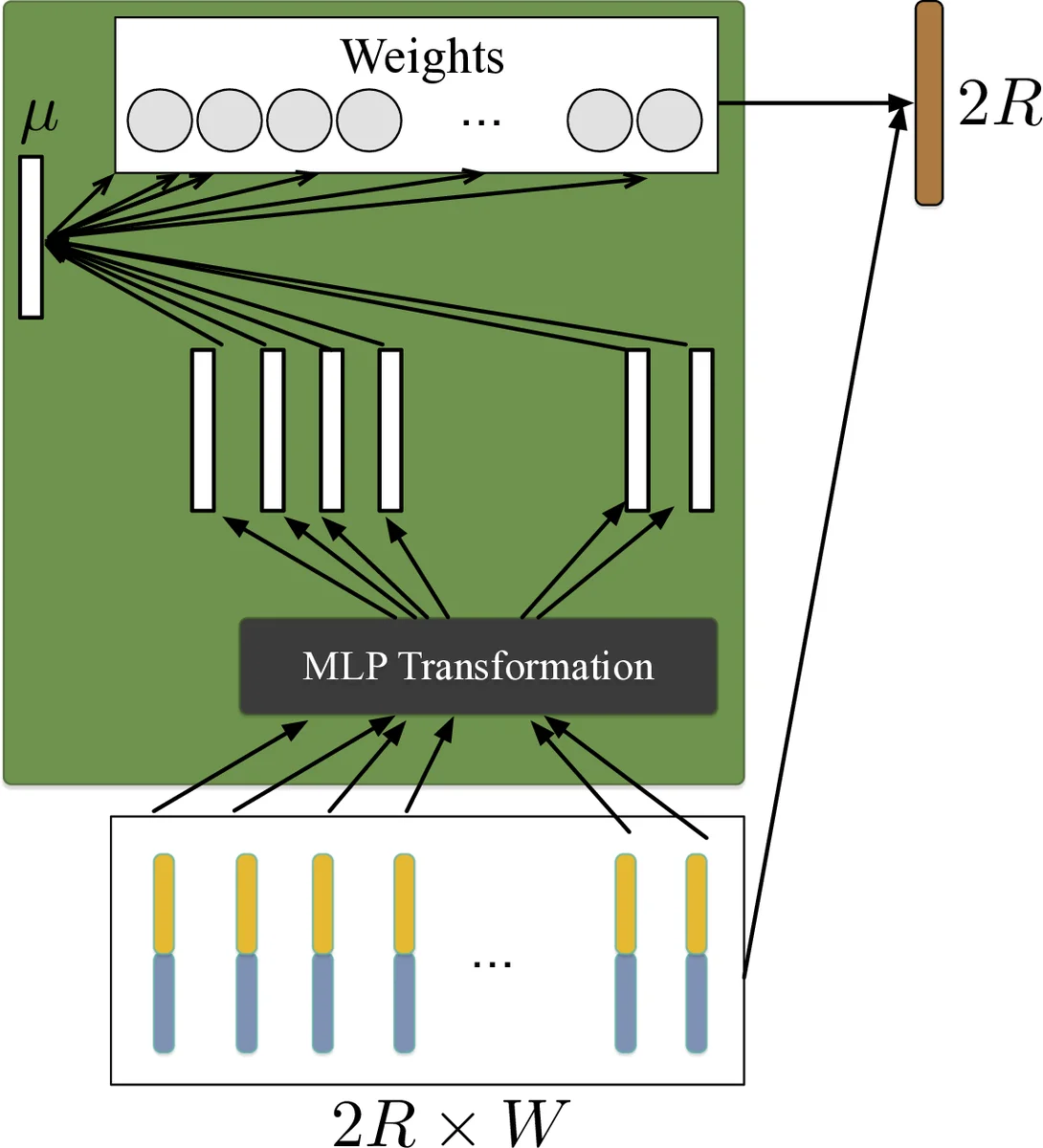
본 연구는 언어 식별(LID)을 “가변 길이 시퀀스 분류” 문제로 정의하고, 기존 i‑vector 기반 방법과 프레임‑레벨 DNN‑기반 방법의 한계를 극복하고자 한다. 핵심 설계는 두 단계로 나뉜다. 첫 번째는 CNN‑BLSTM 전처리 모듈이다. 입력은 64 차원의 로그 멜스펙트럼이며, ResNet‑34 형태의 깊은 CNN이 시간‑주파수 축을 동시에 압축해 C × H × W 형태의 텐서를 만든다. 여기서 H는 주파수 차원, W는 시간 차원(프레임 수)이다. 이후 H 축을 풀링해 2‑차원 C × W 텐서로 변환하고, 양방향 LSTM(BLSTM) 256 유닛을 적용해 전·후향 정보를 모두 활용한다. BLSTM 출력은 2R × W(여기서 R=128) 형태의 가변 길이 시퀀스로, 각 시간 스텝이 발화 전체의 정보를 부분적으로 담고 있다.
두 번째 단계는 자기‑주의 기반 풀링(SAP)이다. BLSTM 출력 시퀀스 {x₁,…,x_T}를 1‑계층 MLP(tanh)로 변환해 {h₁,…,h_T}를 얻고, 학습 가능한 컨텍스트 벡터 μ와의 내적을 소프트맥스로 정규화해 가중치 α_t를 산출한다. 최종 발화 표현 e는 α_t와 x_t의 가중합으로 계산된다. 이 과정은 단순 평균(TAP)과 달리 정보량이 높은 프레임에 더 큰 가중치를 부여해, 특히 긴 발화에서 “마지막 전방 프레임”이나 “첫 번째 후방 프레임”과 같이 중요한 순간을 강조한다.
학습은 SGD(모멘텀 0.9, weight decay 1e‑4)로 진행하며, 배치마다 프레임 수 L을 200~1000 사이에서 무작위로 샘플링해 가변 길이 미니배치를 동적으로 구성한다. 이는 모델이 다양한 길이의 입력에 강건하도록 만든다. 테스트 단계에서는 3 초, 10 초, 30 초 길이의 발화를 그대로 입력해 한 번에 전결 결과를 얻는다.
실험 결과, CNN‑TAP와 CNN‑SAP 대비 각각 9.98%→9.22%(3 초), 3.24%→2.54%(10 초), 1.73%→0.97%(30 초)로 C_avg이 크게 감소했으며, EER 역시 유사하게 개선되었다. 특히 BLSTM을 도입했을 때 TAP만 사용하면 성능이 약간 저하되지만, SAP와 결합하면 가장 우수한 결과를 얻는다. 이는 BLSTM이 제공하는 풍부한 시계열 컨텍스트가 SAP에 의해 효과적으로 활용될 수 있음을 시사한다. 또한, 두 모델(ID2: CNN‑SAP, ID7: CNN‑BLSTM‑SAP)의 점수 융합을 통해 추가적인 오류 감소(예: 3 초 C_avg 7.98%)를 달성하였다.
이 논문은 (1) CNN‑BLSTM을 전처리기로 사용해 지역 패턴과 장기 의존성을 동시에 포착, (2) 자기‑주의 풀링으로 가변 길이 시퀀스를 고정 차원으로 효율적으로 압축, (3) 동적 배치 전략으로 다양한 발화 길이에 대한 일반화 능력을 강화한다는 세 가지 주요 기여를 제시한다. 향후 연구에서는 다중 헤드 주의, 더 깊은 BLSTM 스택, 혹은 Transformer‑ 기반 인코더와의 결합을 통해 더욱 높은 언어 구분 성능을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기