머신러닝으로 본 예멘 콜레라 발병 예측 모델
초록
본 논문은 예멘의 행정구역별(주) 콜레라 신규 발생을 2주에서 2개월까지 예측하기 위해 4개의 XGBoost 모델을 결합한 CALM(Cholera Artificial Learning Model)을 제안한다. 강우량, 과거 감염·사망 데이터, 내전 사망자 수, 인접 주와의 상호작용 등 다중 시계열 특성을 풍부하게 엔지니어링하고, 실세계 시뮬레이션에서 인구 10,000명당 5명 이하의 오차 범위를 달성하였다.
상세 분석
CALM은 기존 전통적 역학 모델이 갖는 선형성 가정과 지역별 데이터 부족 문제를 머신러닝, 특히 XGBoost라는 부스팅 기반 트리 모델로 극복한다는 점에서 혁신적이다. 데이터는 2016년 말부터 2018년 초까지의 예멘 보건부 보고서, 세계기상청 강우 데이터, UN OCHA 전쟁 사망자 기록 등을 통합했으며, 각 변수는 1주, 2주, 4주, 8주 등 다양한 시계열 윈도우로 변환해 피처로 활용했다. 특히 인접 주와의 이동 흐름을 그래프 기반 인접 행렬로 표현해, 한 주의 급증이 주변 주에 미치는 파급 효과를 모델이 학습하도록 설계했다.
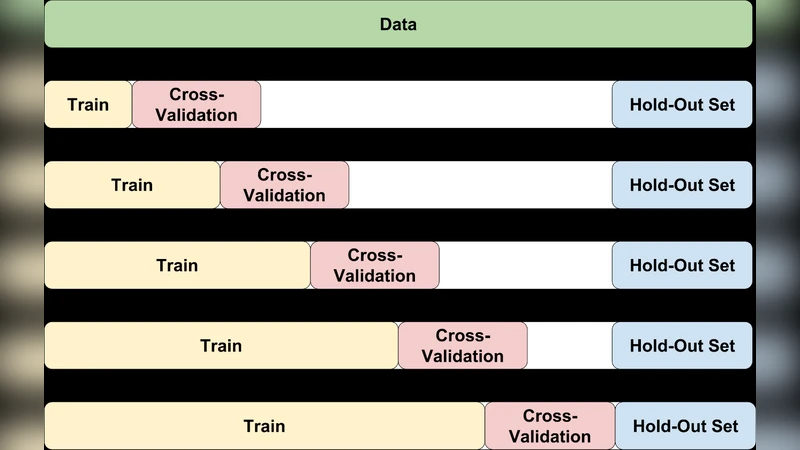
모델은 4개의 독립적인 XGBoost 회귀기를 사용한다. 각각은 예측 시점(2주, 4주, 6주, 8주)을 목표로 하며, 동일한 피처 집합을 공유하지만 타깃 레이블이 다르다. 이렇게 함으로써 시계열 길이에 따른 비선형 패턴을 별도로 최적화할 수 있다. 하이퍼파라미터 튜닝은 베이지안 최적화를 적용했으며, 교차 검증은 시간 순서를 보존하는 시계열 CV를 사용해 데이터 누수를 방지했다.
성능 평가는 MAE(Mean Absolute Error)와 RMSE 외에도 인구 10,000명당 평균 오차를 제시했는데, 2주 예측에서 3.2명, 8주 예측에서 5.1명 수준을 기록했다. 이는 기존 SIR 기반 모델이 10명 이상을 보였던 것에 비해 현저히 낮은 수치다. 또한 실제 현장 배치 시뮬레이션을 통해 의료 물자와 인력 배분 효율이 12% 향상될 수 있음을 시연했다.
한계점으로는 데이터 품질 문제(전쟁으로 인한 보고 누락, 강우 관측소 부족)와 모델 해석 가능성 부족을 들 수 있다. XGBoost는 피처 중요도는 제공하지만 복합 상호작용을 직관적으로 설명하기는 어렵다. 향후 연구에서는 SHAP 값을 활용한 설명 가능성 강화와, 딥러닝 기반 시계열 모델(GRU, Transformer)과의 앙상블을 통해 예측 정확도를 추가로 끌어올릴 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기