연합 학습으로 구현하는 저전력 웨이크워드 탐지: “Hey Snips” 사례 연구
초록
본 논문은 스마트 홈 음성 비서의 웨이크워드 검출 모델을 사용자 데이터를 중앙에 수집하지 않고도 학습할 수 있도록 연합 학습(Federated Learning, FL) 방식을 적용한다. 1,800명 이상의 크라우드소싱 참여자를 통해 수집한 “Hey Snips” 데이터셋을 공개하고, 기존 FedAvg에 Adam‑영감 적응형 평균(Per‑coordinate Adam) 기법을 도입해 통신 라운드 수를 크게 감소시켰다. 10 % 사용자 참여 비율(C=0.1)과 1 epoch 로컬 학습(E=1), 배치 크기 20(B=20) 조건에서 100 라운드(≈8 MB 업로드) 내에 목표 재현율(95 %)과 5 FA/H 기준을 달성하였다.
상세 분석
이 연구는 음성 기반 웨이크워드 검출이라는 특수한 시나리오에 연합 학습을 적용함으로써 두 가지 핵심 과제를 동시에 해결한다. 첫째, 웨이크워드 모델은 항상 켜진 상태로 동작해야 하므로 메모리와 연산량이 극히 제한된다. 논문에서는 190 k 파라미터(≈200 KB) 규모의 CNN‑Dilated 구조를 선택하고, 40‑차원 MFCC를 32프레임 윈도우로 입력한다. 이는 20 MFLOPS 이하의 연산 제한을 만족하면서도 충분한 표현력을 유지한다. 둘째, 사용자 음성 데이터는 개인 정보 보호 측면에서 중앙 수집이 불가능하다. 연합 학습은 로컬 디바이스에서 직접 모델 업데이트를 수행하고, 파라미터만 서버에 전송함으로써 데이터 노출을 최소화한다.
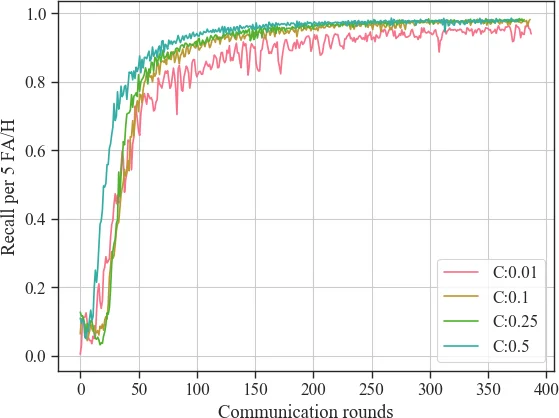
연합 최적화 측면에서 저자들은 기존 FedAvg의 단순 가중 평균을 Adam에서 영감을 얻은 적응형 평균으로 대체하였다. 구체적으로 전 라운드의 모델 차이 (G_t = \sum_{k\in S_t}\frac{n_k}{n_r}(w_{t-1}-w_{t,k})) 에 대해 1차·2차 모멘트를 β₁=0.9, β₂=0.999, ε=10⁻⁸ 로 유지하며, 전역 학습률 η_global=0.001 을 적용한다. 이 방식은 각 파라미터별 업데이트의 스케일을 자동 조정해, 비동질적이고 비IID인 사용자 데이터 분포에서도 안정적인 수렴을 가능하게 한다. 실험 결과, 표준 FedAvg(η_global=1)에서는 400 라운드 이후에도 목표 성능에 도달하지 못했으나, Adam‑기반 평균에서는 100 라운드 내에 98 % 수준의 재현율을 달성했다.
또한, 사용자 참여 비율 C 의 영향을 조사한 결과, C=10 %가 실용적인 트레이드오프임을 확인했다. C가 1 %일 경우 그래디언트 변동성이 커져 학습이 불안정해졌으며, C=50 % 이상으로 늘려도 수렴 속도 향상이 미미했다. 로컬 학습 에폭 E와 배치 크기 B 에 대한 실험에서는 E=1, B=20 조합이 가장 효율적이었다. 이는 과도한 로컬 업데이트가 사용자 간 표현 차이를 확대시켜 전역 평균에 부정적 영향을 미치는 현상을 보여준다.
통신 비용 분석에서는 모델 파라미터(≈8 MB)를 32‑bit 부동소수점으로 전송한다고 가정했으며, C=10 %와 100 라운드 기준으로 사용자당 업로드량이 8 MB, 전체 서버 수신량이 약 110 GB에 달한다. 이는 현재 가정형 가정용 인터넷 환경에서 충분히 감당 가능한 수준이다.
마지막으로, 테스트 셋에서 95 % 재현율을 유지하면서 부정 알람(FAH)은 3.2 ~ 3.9 건 수준으로, 특히 배경 노이즈가 많은 Librispeech 데이터에서도 강인함을 보였다. 이는 연합 학습이 실제 배포 환경에서도 기존 중앙집중식 학습과 동등하거나 우수한 성능을 제공함을 시사한다.
전반적으로 이 논문은 (1) 음성 데이터 특성에 맞춘 경량 CNN 설계, (2) 비IID·비균형 데이터에 강인한 Adam‑기반 전역 평균, (3) 실용적인 사용자 참여 비율과 로컬 학습 설정, (4) 명확한 통신 비용 모델링이라는 네 가지 핵심 요소를 결합해, 프라이버시를 보장하면서도 효율적인 웨이크워드 검출 모델을 학습할 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기