스타일 제어와 전이를 위한 변분 오토인코더 기반 엔드투엔드 TTS
초록
본 논문은 변분 오토인코더(VAE)를 Tacotron2 기반 엔드투엔드 텍스트‑투‑스피치(TTS) 시스템에 결합하여, 화자의 말하기 스타일을 무감독 방식으로 잠재 공간에 학습한다. 학습된 잠재 변수는 차원별로 피치 높이, 피치 변동, 발화 속도 등 스타일 요소를 독립적으로 제어할 수 있으며, 참조 음성을 통해 추출한 스타일 벡터를 TTS에 주입함으로써 스타일 전이도 가능하게 한다. KL 발산 붕괴 문제를 완화하기 위해 KL annealing과 단계적 적용을 도입했으며, 실험 결과 GST 기반 모델을 ABX 청취 테스트에서 유의미하게 능가함을 보였다.
상세 분석
이 연구는 기존의 엔드투엔드 TTS가 주로 중립적인 음성 품질에 집중해 온 반면, 표현력 있는 스타일 제어·전이에 초점을 맞추었다는 점에서 의미가 크다. 변분 오토인코더(VAE)를 Tacotron2의 텍스트 인코더와 결합함으로써, 입력 텍스트와 별개로 스타일을 담당하는 연속적인 잠재 변수 z 를 학습한다. 인코더는 6개의 2‑D 컨볼루션 레이어와 GRU로 구성된 레퍼런스 인코더를 사용해 음성 특징을 압축하고, 두 개의 전결합층을 통해 μ와 σ 를 출력한다. 재파라미터화 트릭을 통해 샘플링된 z 는 텍스트 인코더 출력에 차원 맞춤 전결합층을 거쳐 합산되며, 이후 위치‑감도 어텐션과 디코더가 멜 스펙트로그램을 생성한다.
KL 발산이 학습 초기에 급격히 감소해 인코더가 무력화되는 ‘KL 붕괴’ 현상을 방지하기 위해, 저자는 KL 가중치를 점진적으로 증가시키는 KL annealing과 일정 스텝마다 KL 손실을 적용하는 두 가지 트릭을 동시에 사용했다. 이로써 z 가 의미 있는 정보를 유지하도록 유도한다.
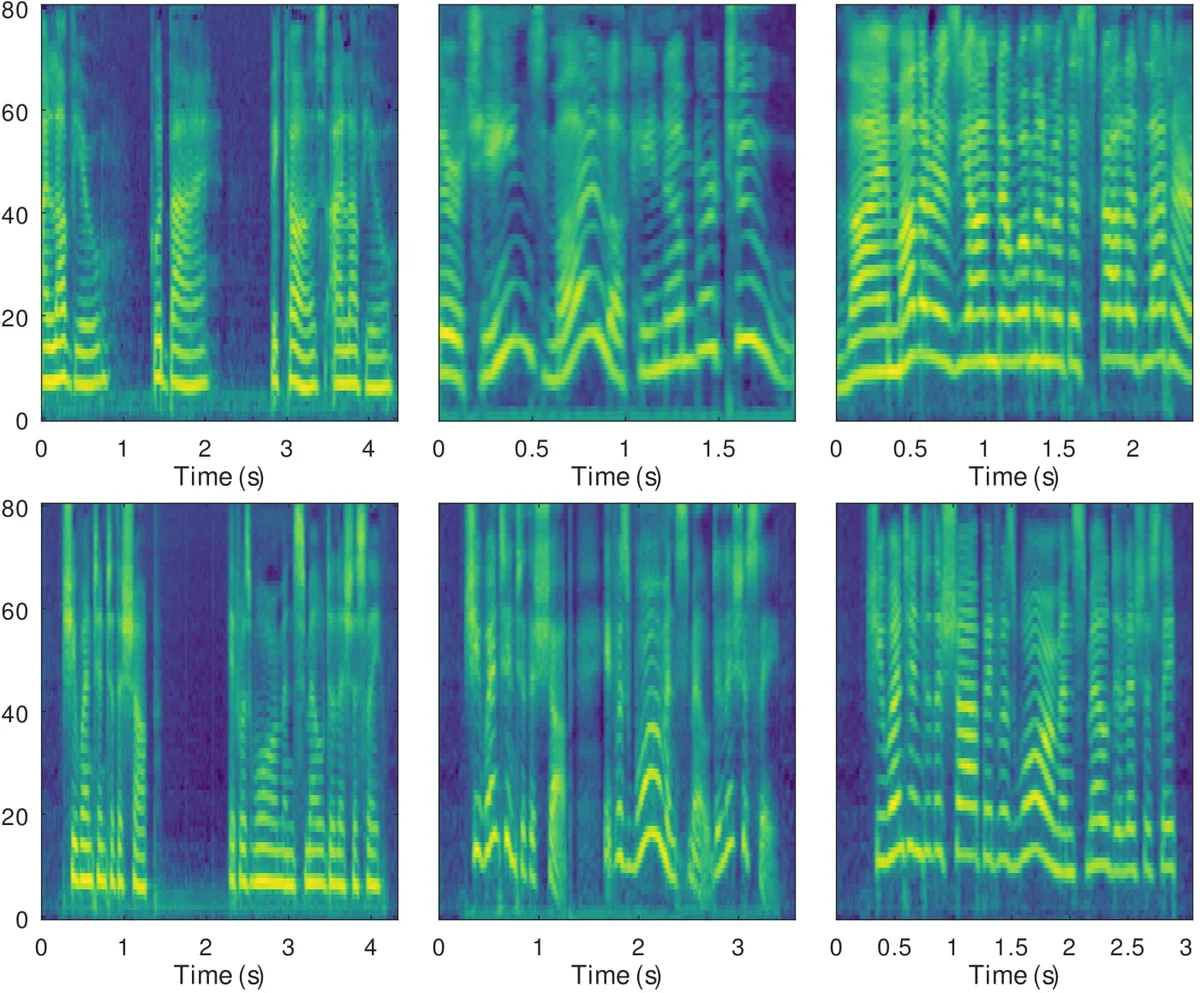
잠재 공간의 연속성은 두 스타일(고음·고속 vs 저음·저속) 사이를 선형 보간함으로써 시각적으로 확인했으며, 차원별 조작 실험을 통해 피치 높이, 피치 변동, 발화 속도 등 특정 스타일 요소가 개별 z 차원에 매핑됨을 입증했다. 특히 차원 6 은 피치 높이, 차원 10 은 피치 변동을 제어했으며, 두 차원을 동시에 활성화하면 두 효과가 선형적으로 합성되는 것을 확인했다.
스타일 전이 실험에서는 레퍼런스 음성으로부터 z 를 추출한 뒤 동일 텍스트를 합성했을 때, 멜 스펙트로그램이 레퍼런스와 유사한 피치 패턴·휴지기·속도를 보였다. 청취자 대상 ABX 테스트(병렬·비병렬 전이 모두)에서 제안 모델은 GST 기반 베이스라인보다 유의미하게 높은 선호도를 얻었으며, 특히 비병렬 전이에서 일반화 능력이 뛰어남을 확인했다.
전체적으로 이 논문은 VAE를 활용한 스타일 잠재 변수 학습이 TTS 시스템에 자연스럽고 직관적인 스타일 제어·전이 메커니즘을 제공한다는 점을 실증했으며, KL 붕괴 해결 방안과 잠재 변수의 해석 가능성 탐구가 향후 연구에 중요한 토대를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기