회귀 기반 퍼지 모델을 활용한 소프트웨어 개발 노력 추정
초록
본 연구는 회귀 분석을 활용해 설계한 세 가지 퍼지 로직 모델(Mamdani, Sugeno‑상수, Sugeno‑선형)을 ISBSG 산업 데이터에 적용하고, 표준화 정확도·효과 크기·균형 상대 오차 등 최신 평가 지표와 통계 검증을 통해 성능을 비교한다. 데이터의 이분산성과 이상치에 대한 민감성을 확인한 결과, 회귀 설계가 적용된 Sugeno‑선형 모델이 가장 우수한 추정 정확도를 보였다.
상세 분석
이 논문은 소프트웨어 개발 노력 추정이라는 고난이도 문제에 대해 퍼지 로직과 회귀 분석을 결합한 ‘회귀 퍼지 모델(regression fuzzy)’ 접근법을 제시한다. 먼저, 기존 연구에서 머신러닝, 특히 퍼지 시스템이 불확실하고 잡음이 많은 입력 변수들을 다루는 데 강점을 보인다는 점을 강조한다. 세 가지 퍼지 추론 시스템을 설계했는데, Mamdani 모델은 전통적인 규칙 기반 출력이 구간 형태이며, Sugeno‑상수 모델은 각 규칙마다 고정된 스칼라 값을 출력한다. 가장 혁신적인 부분은 Sugeno‑선형 모델로, 각 규칙의 출력이 입력 변수의 선형 결합 형태를 갖도록 설계했으며, 이를 위해 사전 회귀 분석을 수행해 변수 간 관계와 가중치를 사전에 추정한다. 회귀 분석 결과는 멤버십 함수의 중심과 폭을 결정하는 데 사용되어, 퍼지 규칙이 데이터 분포에 보다 정밀히 맞춰지도록 한다.
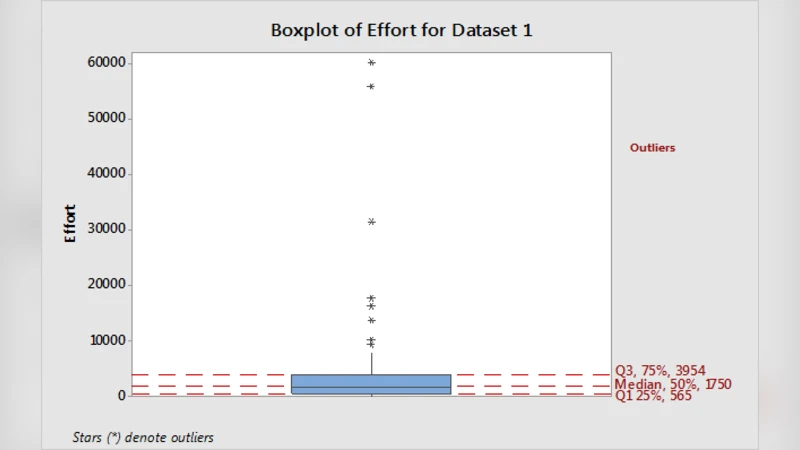
실험 데이터는 ISBSG 데이터베이스에서 추출한 산업 현장 프로젝트(수천 건)이며, 데이터 전처리 단계에서 결측값 제거, 로그 변환, 정규화 등을 적용했다. 특히, 데이터가 이분산(heteroscedastic) 특성을 보이며, 일부 프로젝트는 극단적인 노력값을 갖는 이상치(outlier)로 나타났다. 이러한 특성은 모델 학습에 큰 영향을 미치는데, 논문은 회귀 기반 설계가 이분산성을 완화시키는 데 제한적이며, 이상치에 대한 민감도가 여전히 높다는 점을 실증한다.
평가 지표로는 표준화 정확도(Standardized Accuracy, SA), 효과 크기(Effect Size, ES), 평균 균형 상대 오차(MBRe) 등을 사용했으며, 이는 기존의 MRE, MMRE와 달리 편향을 보정하고 비교 가능성을 높인다. 통계 검증으로는 Friedman 검정 후 Nemenyi 사후 검정을 적용해 모델 간 차이를 검증하였다. 결과는 Sugano‑선형 모델이 SA와 ES에서 가장 높은 값을 기록했으며, MBRe 역시 가장 낮은 수준을 보였다. Mamdani와 Sugano‑상수 모델은 비슷한 수준이었지만, 두 모델 모두 이상치가 포함된 경우 성능이 급격히 저하되는 경향을 보였다.
결론적으로, 회귀 분석을 통해 퍼지 규칙을 데이터‑드리븐하게 설계하면, 특히 Sugano‑선형 구조가 복잡한 비선형 관계와 이분산성을 어느 정도 보정하면서도 높은 예측 정확도를 달성한다는 점을 확인했다. 다만, 데이터 전처리 단계에서 이상치 탐지·제거 혹은 로버스트 회귀 기법을 병행하는 것이 모델의 안정성을 크게 향상시킬 수 있다. 향후 연구에서는 다중 목표(시간·비용·품질) 추정, 온라인 학습 기반 퍼지 시스템, 그리고 다른 회귀 기반 퍼지 변형(예: ANFIS)과의 비교를 통해 일반화 가능성을 검증할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기