CEM RL 진화와 그래디언트 기반 방법을 결합한 정책 탐색
초록
본 논문은 진화 전략인 교차 엔트로피 방법(CEM)과 최신 오프‑폴리시 강화학습 알고리즘인 TD3를 결합한 CEM‑RL을 제안한다. 인구 기반의 파라미터 탐색과 비평가 네트워크를 통한 그래디언트 업데이트를 순환적으로 수행함으로써 샘플 효율성과 학습 안정성을 동시에 향상시킨다. 실험 결과, 기존 CEM, TD3, 그리고 ERL(진화‑강화 학습) 대비 더 빠른 수렴과 낮은 변동성을 보이며, 다양한 연속 제어 벤치마크에서 경쟁력 있는 성능을 달성한다.
상세 분석
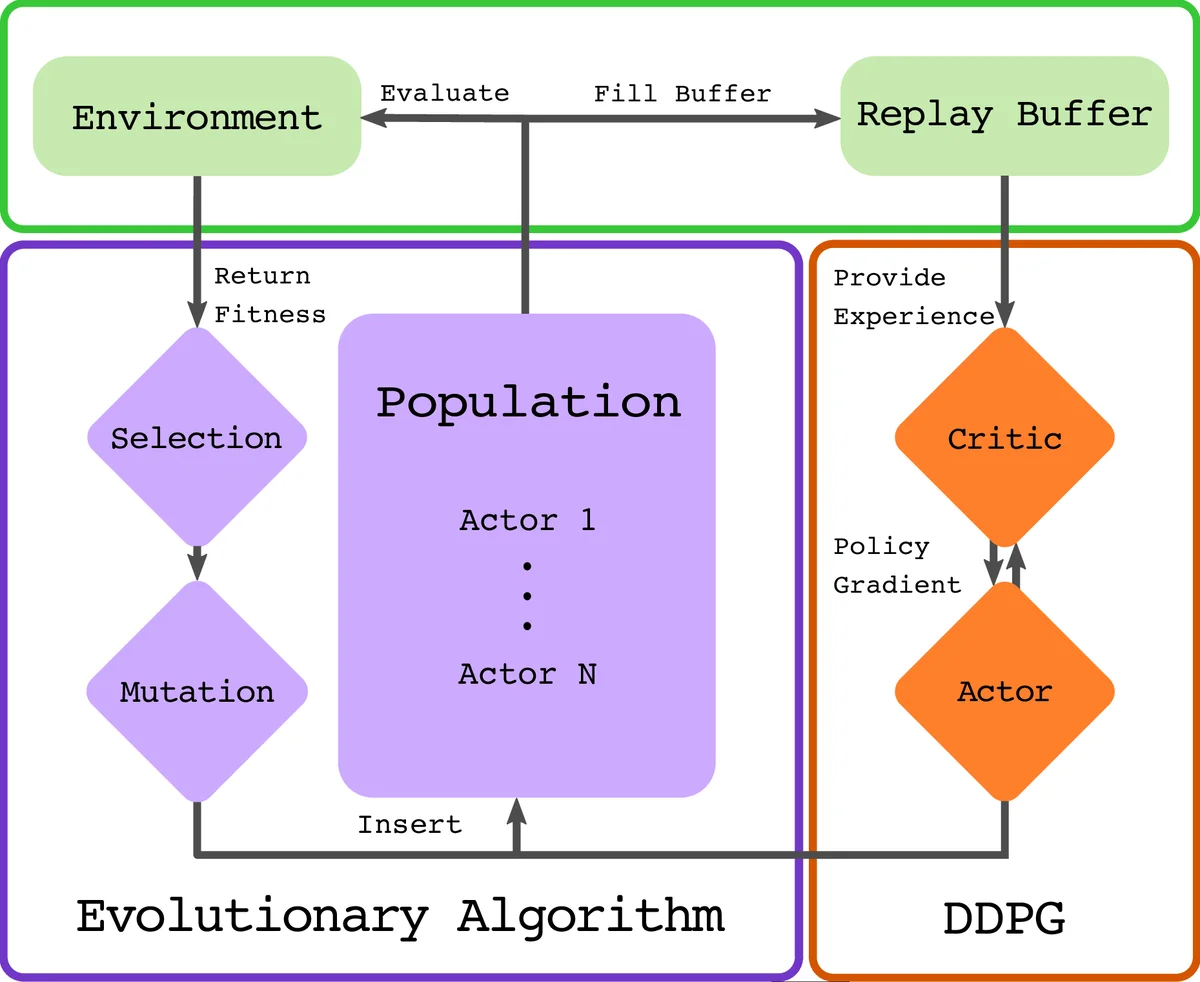
CEM‑RL은 두 가지 핵심 아이디어를 결합한다. 첫째, 교차 엔트로피 방법(CEM)은 인구(population) 수준에서 파라미터를 가우시안 분포로 샘플링하고, 상위 엘리트(elite) 샘플을 이용해 평균 µ와 공분산 Σ를 업데이트한다. 이때 공분산은 대각선으로 제한하고, 사전 정의된 초기 표준편차 σ_init에서 최종 σ_end까지 지수적으로 감소시키는 τ_cem 스케줄을 적용해 조기 수렴을 방지한다. 둘째, TD3는 두 개의 크리틱 네트워크와 목표 정책 네트워크를 사용해 과대평가(bias)를 완화하고, 정책 지연(policy delay) 기법으로 정책 업데이트 빈도를 낮춰 안정성을 높인다.
알고리즘 흐름은 다음과 같다. 초기에는 무작위 정책 π_µ 와 크리틱 Q_π 를 생성한다. 매 반복마다 현재 µ와 Σ로부터 pop_size 개의 정책을 샘플링하고, 절반은 그대로 환경에 적용해 에피소드 보상을 측정한다. 나머지 절반에 대해서는 현재 크리틱 Q_π 가 제공하는 행동‑가치 그래디언트를 이용해 n_grad 스텝(논문에서는 actor_steps / (pop_size/2) 스텝)만큼 정책을 개선한다. 이렇게 그래디언트‑향상된 정책도 동일하게 평가하고, 전체 pop_size 개의 보상 데이터를 리플레이 버퍼 R에 저장한다. 이후 크리틱은 새로 들어온 |R| 샘플에 비례해 mini‑batch 학습을 수행하고, 정책은 TD3의 목표 네트워크와 클리핑된 노이즈를 사용해 업데이트된다. 마지막으로, 전체 인구 중 상위 pop_size/2 개의 정책을 선택해 새로운 µ와 Σ를 재계산한다.
이 구조의 장점은 크게 세 가지로 요약할 수 있다. (1) 샘플 효율성: TD3가 리플레이 버퍼에서 동일 샘플을 여러 차례 재사용함으로써 CEM 단독 대비 10배 이상 효율을 높인다. (2) 안정성: CEM은 전역 탐색을 담당해 급격한 정책 변동을 억제하고, TD3는 로컬 최적화를 담당해 빠른 수렴을 돕는다. 두 메커니즘이 서로 보완적으로 작용해 학습 과정에서 발생하는 발산 현상을 크게 감소시킨다. (3) 다양성 유지: 그래디언트 스텝을 적용한 정책이 성능을 저하시키면 CEM 단계에서 자동으로 제외되므로, 불필요한 탐색 경로가 버퍼에만 남아 추가적인 탐색 정보를 제공한다. 이는 ERL에서와 달리 진화 단계가 그래디언트 단계에 직접적인 영향을 받지 않아, 탐색 다양성을 보존한다는 의미이다.
실험에서는 MuJoCo 기반 연속 제어 환경인 HalfCheetah‑v2, Hopper‑v2, Walker2d‑v2, Ant‑v2 등을 사용했다. CEM‑RL은 동일한 하이퍼파라미터 설정 하에 ERL과 비교했을 때, 초기 학습 단계에서 더 높은 평균 보상을 기록했으며, 최종 수렴점에서도 경쟁력 있는 혹은 더 우수한 성능을 보였다. 특히, 표준 편차가 큰 환경(Ant)에서 변동성이 현저히 낮아, 실제 로봇 적용 시 안정적인 정책을 제공한다는 점이 강조된다.
한계점으로는 공분산을 대각선으로 제한함으로써 고차원 파라미터 공간에서의 탐색 효율이 다소 저하될 수 있다는 점, 그리고 τ_cem 과 σ_init/σ_end 같은 하이퍼파라미터가 여전히 성능에 큰 영향을 미친다는 점을 들 수 있다. 향후 연구에서는 공분산 구조를 저차원으로 압축하는 방법이나, 자동화된 하이퍼파라미터 튜닝 기법을 도입해 이러한 제약을 완화할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기