디지털 뉴런: 초저전력 임베디드용 고성능 CNN 가속기
초록
본 논문은 정수 입력·가중치를 이용해 8‑bit 연산을 3개의 부분 정수와 배럴 쉬프터만으로 구현함으로써 회로 면적과 전력 소모를 크게 줄인 ‘디지털 뉴런’ 하드웨어 가속기를 제안한다. 1클럭당 800 MAC을 수행하고, DRAM 접근을 최소화한 데이터 재사용 구조와 가변 필터 크기를 지원하는 구성 가능 아키텍처를 통해 754.7 GMAC/W라는 높은 효율을 달성한다.
상세 분석
이 논문은 임베디드 시스템에서 CNN 추론을 수행하기 위한 전용 하드웨어 설계인 ‘디지털 뉴런(Digital Neuron)’을 상세히 제시한다. 핵심 아이디어는 8‑bit 정수 가중치를 2~3개의 ‘부분 정수(partial sub‑integer)’로 분해하고, 각각을 배럴 쉬프터(barrel shifter)와 단순 멀티플렉서로 구현함으로써 전통적인 부스(Booth) 곱셈기 대비 회로 면적과 전력 소모를 크게 감소시키는 것이다. 3개의 부분 정수를 사용하면 최대 2 % 정도의 양자화 오차만 발생하며, LeNet‑5와 MNIST 데이터셋 실험에서 99.10 %의 정확도를 유지한다(표 I).
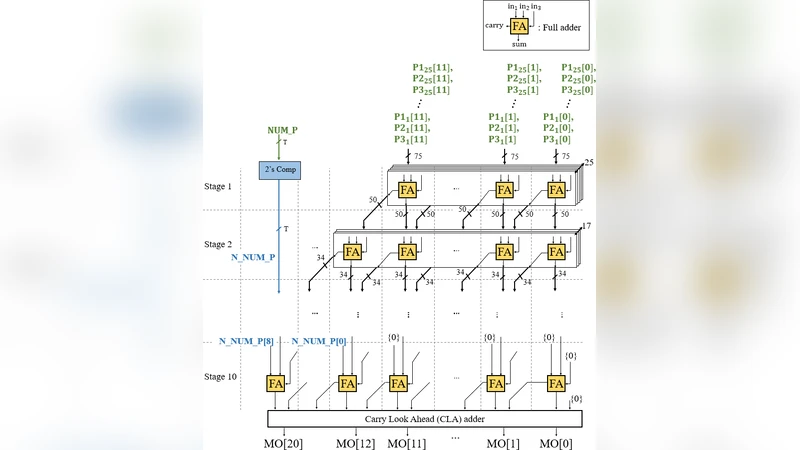
연산 엔진은 ‘Multiplication by Barrel Shift(MBS)’ 블록과 ‘Multi‑Operand Adder(MOA)’ 블록으로 구성된다. MBS는 입력 가중치를 3개의 배럴 쉬프터에 연결해 P1, P2, P3라는 세 부분 곱을 생성하고, 제어 신호(a, b, c, …)를 통해 양/음 입력을 선택한다. 이후 MOA는 Wallace‑tree 형태의 다중 가산기를 사용해 3N개의 부분 곱을 단계적으로 합산한다. 이 과정에서 부호 확장은 2’s complement 회로만으로 대체해 면적 증가를 21 % 이하로 억제한다.
시스템 수준에서는 8 × 5 × 5 형태의 ‘Neural Tile(NT)’을 4개 배치해 3D 필터 연산과 완전 연결(FC) 연산을 동시에 1클럭에 수행한다. 가중치는 w‑bank 레지스터에 한 번 로드한 뒤 모든 레이어에서 재사용하고, 입력 피처맵은 X‑bus를 통해 슬라이딩 윈도우 방식으로 순차적으로 공급한다. 이렇게 함으로써 DRAM 접근을 최소화하고, 데이터 재사용 효율을 극대화한다.
또한 설계는 필터 크기에 따라 NT와 CLA 가산기의 연결 방식을 동적으로 재구성할 수 있는 ‘구성 가능 스킴’을 제공한다. 예를 들어 3 × 3, 5 × 5, 7 × 7 등 다양한 커널에 대해 NT를 부분적으로 할당하고, 출력은 CLA 가산기로 합산해 최종 피처맵을 만든다. 이는 하드웨어 자원을 효율적으로 활용하면서도 다양한 네트워크 구조에 대응할 수 있게 한다.
성능 측면에서 제안된 디지털 뉴런은 1클럭당 800 MAC을 수행하고, 전력 효율은 754.7 GMAC/W에 달한다. 이는 기존의 UNPU, BIT‑FUSION 등과 비교해 면적·전력·처리량 모두에서 우수함을 의미한다. 특히 5‑bit 가중치와 3‑partial‑sub‑integer 방식을 사용하면서도 32‑bit 부동소수점 기준 정확도 손실이 거의 없다는 점은 임베디드 AI 적용에 큰 장점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기