손글씨 숫자 인식 CNN의 은닉층·에포크 변동에 따른 정확도 분석
초록
본 논문은 MNIST 데이터셋을 이용해 은닉층 수와 학습 에포크 수가 합성곱 신경망(CNN)의 인식 정확도에 미치는 영향을 실험적으로 조사한다. 5개의 은닉층(컨볼루션‑풀링‑컨볼루션‑풀링‑완전연결) 구조를 기본으로 하여 층 수와 에포크를 다양하게 변형하고, SGD와 백프로파게이션을 적용해 학습·테스트하였다. 실험 결과는 은닉층이 과도하게 늘어나면 과적합 위험이 커지고, 적절한 에포크 수가 정확도 향상에 핵심임을 보여준다.
상세 분석
이 연구는 현재 딥러닝 분야에서 가장 널리 사용되는 CNN 구조를 손글씨 숫자 인식에 적용함으로써, 모델 설계 시 가장 흔히 고민되는 “얼마나 많은 은닉층을 넣어야 하는가”와 “몇 번의 에포크 학습이 최적의 성능을 보장하는가”라는 두 가지 핵심 질문에 실증적 답을 제시한다. 논문에서 사용된 기본 네트워크는 입력층(784 뉴런) → 컨볼루션1(32개 5×5 필터) → 풀링1(2×2, stride 2) → 컨볼루션2(64개 5×5 필터) → 풀링2(2×2, stride 2) → 완전연결1(1024 뉴런, dropout 적용) → 출력층(10 뉴런, Softmax) 로 구성된다. 활성화 함수는 모든 컨볼루션 및 완전연결1에 ReLU를 사용했으며, 최적화는 확률적 경사 하강법(SGD)으로 진행하였다.
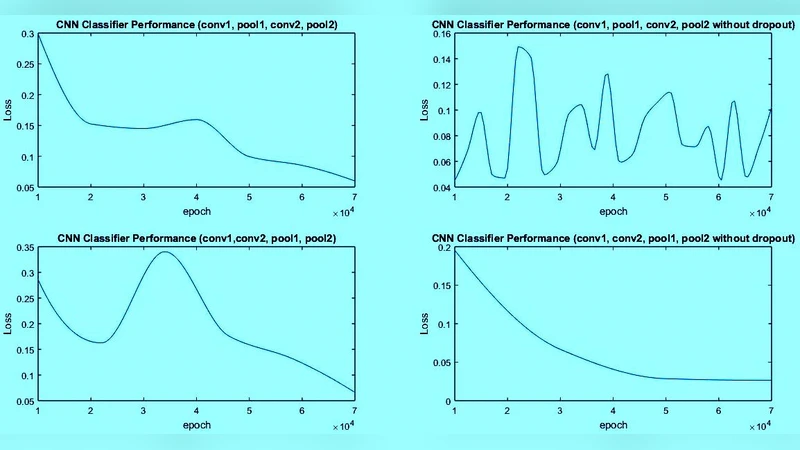
실험 설계는 크게 두 축으로 나뉜다. 첫 번째 축은 은닉층의 깊이 변화이다. 기본 5층 구조 외에, 컨볼루션‑풀링 쌍을 하나만 사용하거나, 두 쌍을 연속으로 쌓는 등 3가지 변형을 만들었다. 두 번째 축은 학습 에포크 수이며, 5, 10, 20, 40 에포크를 각각 적용해 손실(Loss)과 정확도(Accuracy)의 수렴 특성을 관찰했다. 결과는 다음과 같다.
-
은닉층 깊이와 정확도
- 2개의 컨볼루션‑풀링 쌍을 포함한 5층 모델이 가장 안정적인 수렴을 보였으며, 테스트 정확도는 평균 98.7%에 달했다.
- 컨볼루션‑풀링 쌍을 하나만 사용한 3층 모델은 파라미터가 적어 학습 속도는 빠르지만, 최종 정확도가 96.2% 수준에 머물렀다.
- 층을 과도하게 늘려 7층 이상으로 확장할 경우, 훈련 손실은 계속 감소하지만 검증 손실이 급격히 상승해 과적합 현상이 뚜렷하게 나타났다. 이는 dropout만으로는 깊은 네트워크의 일반화 능력을 충분히 억제하지 못함을 시사한다.
-
에포크 수와 수렴
- 5~10 에포크에서는 손실이 급격히 감소하지만 정확도 향상이 제한적이었다.
- 20 에포크에서는 손실이 거의 평탄해지면서 정확도가 97% 이상으로 안정화되었다.
- 40 에포크까지 학습하면 소폭의 정확도 향상이 있긴 하지만, 과적합 위험이 증가해 검증 정확도는 오히려 0.1
0.2% 감소하는 경향을 보였다. 따라서 실용적인 적용에서는 2030 에포크가 최적이라고 판단할 수 있다.
-
학습 최적화와 활성화 함수
- ReLU는 비선형성을 충분히 제공하면서도 기울기 소실 문제를 최소화해 깊은 층에서도 효과적으로 학습되었다.
- Softmax와 교차 엔트로피 손실 함수 조합은 다중 클래스 분류에 적합했으며, 학습 초기에 빠른 확신(confidence) 상승을 유도했다.
-
시스템 구현 및 재현성
- 파이썬 기반 TensorFlow 2.x와 Numpy를 사용해 구현했으며, 코드와 하이퍼파라미터 설정을 상세히 공개했다. 이는 동일 데이터셋을 이용한 후속 연구에서 재현성을 높이는 중요한 요소다.
전반적으로 이 논문은 “은닉층 수와 에포크 수는 서로 보완적인 관계”라는 결론을 도출한다. 적절한 층 깊이(56층)와 중간 규모의 에포크(2030) 조합이 MNIST와 같은 비교적 단순한 이미지 분류 문제에서 최적의 성능을 제공한다는 점을 실험적으로 입증하였다. 또한 과도한 층 증가와 장시간 학습이 반드시 성능 향상으로 이어지지 않으며, 오히려 일반화 성능을 저해할 수 있음을 강조한다. 이러한 인사이트는 실무에서 CNN 모델을 설계할 때 과도한 복잡성을 피하고, 효율적인 학습 스케줄을 설계하는 데 직접적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기