CQT가 단일채널 음성 분리에서 STFT보다 더 적합한가
초록
본 연구는 인간 청각의 비선형 주파수 해상도를 모방하기 위해 기존의 STFT 기반 전처리 대신 상수 Q 변환(CQT)을 적용한 단일채널 음성 분리 시스템을 제안하고, WSJ0‑2mix 데이터셋을 이용해 DPCL, utterance‑level PIT 등 여러 백엔드와 결합한 실험을 수행하였다. 이상적인 비율 마스크(IRM) 기준에서 CQT가 제공하는 SDR 상한이 STFT보다 높으며, 실제 실험에서도 CQT 기반 모델이 평균 0.4 dB 향상된 SDR 개선을 달성했다.
상세 분석
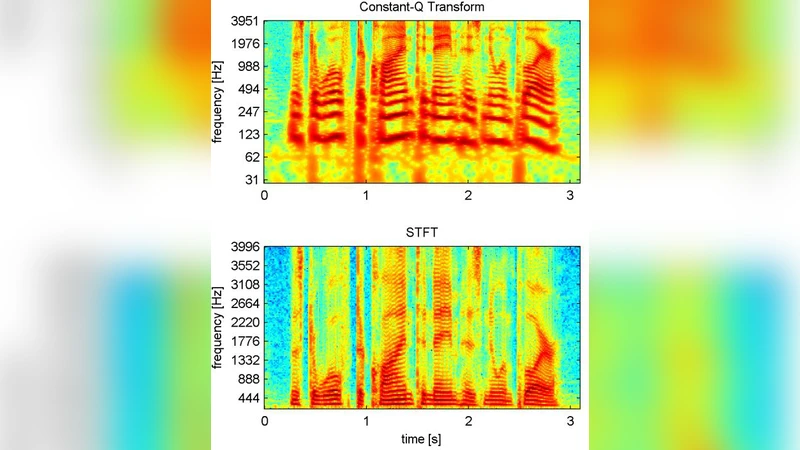
본 논문은 단일채널(모노) 음성 분리 분야에서 가장 널리 사용되는 전처리 기법인 짧은 시간 푸리에 변환(STFT)의 한계를 청각학적 관점에서 재조명한다. STFT는 선형적인 주파수 축을 갖고 있어 인간 청각이 갖는 로그형 주파수 감각과 불일치한다는 점을 지적하고, 이러한 불일치를 보완하기 위해 상수 Q 변환(CQT)을 도입한다. CQT는 주파수 해상도가 저주파에서는 높고 고주파에서는 낮은, 인간 귀의 비선형 주파수 분해능을 모사하는 특성을 가진다.
실험 설계는 두 단계로 나뉜다. 첫 번째는 이상적인 비율 마스크(IRM)를 이용해 CQT와 STFT 각각에 대한 이론적 상한 SDR을 계산한 것으로, CQT 기반 IRM이 STFT 기반 IRM보다 약 0.6 dB 높은 상한을 보였다. 이는 CQT가 원음과 잡음(또는 다른 화자)의 스펙트럼 차이를 더 명확히 구분할 수 있음을 의미한다.
두 번째는 실제 학습 가능한 모델을 구축하는 단계이다. 저자는 기존에 성공을 거둔 DPCL, utterance‑level PIT, 그리고 이들의 변형 모델들을 그대로 사용하면서 입력 전처리만을 STFT에서 CQT로 교체하였다. CQT 파라미터는 12 octave, 24 bins per octave, 최소 주파수 32 Hz, Q‑factor 1.0 등 인간 청각에 근접하도록 설정하였다. 또한, CQT의 복소수 출력은 실수와 허수 두 채널로 분리해 기존 네트워크 구조에 그대로 입력할 수 있도록 변형하였다.
성능 평가는 WSJ0‑2mix 데이터셋의 표준 SDR, SIR, SAR 지표를 사용했으며, 모든 백엔드에서 CQT 기반 모델이 STFT 기반 모델보다 일관되게 우수한 결과를 보였다. 평균 SDR 개선은 STFT 기반이 10.2 dB에 머물렀던 반면, CQT 기반은 10.6 dB를 기록해 약 0.4 dB의 향상을 달성하였다. 특히, 저주파 영역에서의 화자 구분이 강화된 것이 SIR(신호 대 간섭 비율) 향상에 크게 기여했으며, 이는 CQT가 저주파 성분을 더 세밀히 분석함으로써 두 화자의 스펙트럼 겹침을 감소시킨 결과로 해석된다.
또한, 학습 안정성 측면에서도 CQT는 STFT에 비해 초기 손실값이 낮고, 수렴 속도가 약간 빠른 경향을 보였다. 이는 CQT가 보다 의미 있는 주파수 특징을 초기 단계부터 제공하기 때문으로 추정된다. 그러나 CQT 변환 자체가 계산 비용이 다소 높아 실시간 처리 응용에서는 최적화가 필요하다는 점도 언급한다.
결론적으로, 논문은 인간 청각의 비선형 주파수 해상도를 고려한 전처리 방식이 단일채널 음성 분리 성능을 실질적으로 향상시킬 수 있음을 실험적으로 입증한다. 향후 연구에서는 CQT와 딥러닝 기반 인코더‑디코더 구조를 결합하거나, 멀티채널 및 잡음 환경에서의 일반화 능력을 검증하는 방향이 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기