Spark와 MPI OpenMP를 활용한 워드카운트 성능 비교
초록
본 논문은 MPI와 OpenMP 기반의 고성능 MapReduce 구현을 제안하고, 이를 Apache Spark와 동일한 AWS r5.xlarge 클러스터에서 2 GB 텍스트 워드카운트 작업에 적용해 비교한다. 실험 결과, MPI/OpenMP 구현이 Spark보다 약 10배, 즉 300 % 이상 빠른 성능을 보이며, 이는 C++ 네이티브 실행, 결함 허용 설계 생략, 그리고 맵 단계에서의 로컬 축소(local reduce)와 효율적인 해시 테이블 구조 덕분이라고 주장한다.
상세 분석
논문은 먼저 MapReduce 패러다임을 고성능 컴퓨팅 환경에 맞게 재구성한다는 점에서 흥미롭다. 핵심 데이터 구조인 DistRange, DistHashMap, ConcurrentHashMap을 도입해 분산 및 공유 메모리에서의 효율적인 키‑값 삽입·업데이트를 구현한다. DistRange는 시작·끝·스텝을 지정해 전역 인덱스 공간을 각 노드·스레드에 균등하게 할당하고, 사용자 정의 매퍼 함수를 통해 각 숫자를 처리한다. 매퍼는 로컬 스레드 캐시(스레드‑전용 선형 탐사 해시)로 충돌을 회피하고, 메인 ConcurrentHashMap에 비동기적으로 병합한다.
ConcurrentHashMap은 세그먼트 기반 선형 탐사(hash probing) 방식을 채택해 메모리 할당을 최소화하고, 체이닝 방식보다 캐시 친화적이다. 세그먼트가 이미 잠겨 있으면 스레드 로컬 버퍼에 데이터를 임시 저장하고, 맵 단계 종료 시점에 일괄 동기화한다. 이러한 설계는 스레드 간 락 경쟁을 크게 감소시켜 멀티코어 환경에서 높은 스루풋을 달성한다.
DistHashMap은 각 노드에 메인 ConcurrentHashMap과 다른 노드용 보조 맵을 유지한다. 맵 단계가 끝나면 모든 노드가 자체 파티션에 해당하는 키‑값 쌍을 서로 교환(shuffle)하고, 수신된 데이터를 병렬 삽입한다. 여기서 “eventual consistency”를 허용함으로써 복잡한 동기화 프로토콜을 배제하고, 네트워크 트래픽을 최소화한다. 특히, 매퍼가 로컬에서 이미 같은 키에 대한 합계를 수행하는 로컬 리듀스(local reduce) 전략은 셔플 단계에서 전송되는 레코드 수를 크게 줄인다.
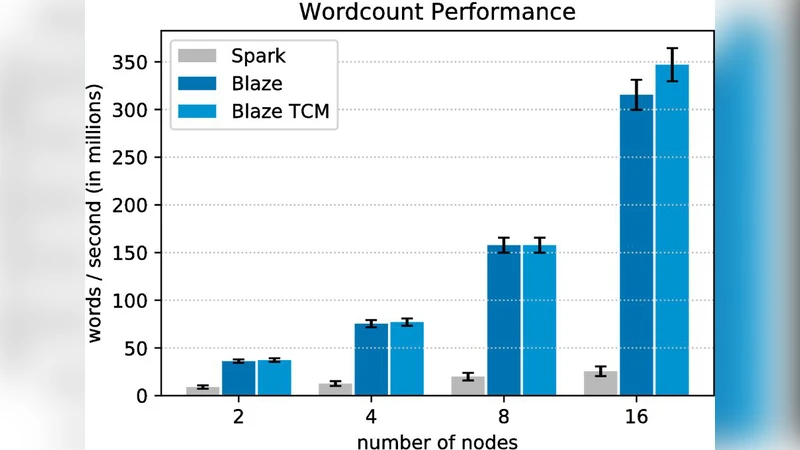
실험 환경은 AWS EMR Spark 2.4.0과 MPICH 3.2 기반 MPI/OpenMP을 동일한 r5.xlarge 인스턴스(4 vCPU, 32 GB) 4대 클러스터에 배치했다. 입력 데이터는 성경·셰익스피어 텍스트를 200배 반복해 약 2 GB 규모로 만든다. 성능 지표는 초당 처리 단어 수(words per second)이며, MPI/OpenMP 구현이 Spark 대비 10배 이상 빠른 결과를 보였다.
논문이 제시한 성능 차이는 크게 세 가지 요인으로 설명한다. 첫째, C++ 네이티브 코드와 MPICH/OpenMP 런타임이 JVM·Scala 인터프리터보다 낮은 오버헤드를 가진다. 둘째, Spark는 내장된 장애 복구 메커니즘(라인 로그, 체크포인팅 등)으로 인해 추가적인 I/O와 메모리 사용이 발생한다. 셋째, 로컬 리듀스와 효율적인 해시 테이블 설계가 네트워크 I/O를 크게 감소시킨다.
하지만 논문은 몇 가지 한계도 내포한다. 구현이 결함 허용을 전혀 고려하지 않아 장시간 실행 시 장애 발생 시 재시작이 필요하다. 또한, 실험은 워드카운트라는 I/O‑집중형, 키‑값 빈도가 높은 작업에 국한돼 있어, 복잡한 조인이나 다단계 파이프라인에 대한 일반화 가능성은 검증되지 않았다. 코드 공개는 GitHub에 제한된 브랜치만 제공하고, 재현성을 위해 정확한 컴파일 옵션·MPI 환경 변수 등이 상세히 기술되지 않았다.
전반적으로, 논문은 고성능 컴퓨팅 환경에서 MapReduce를 구현할 때 전통적인 Hadoop‑계열 프레임워크보다 낮은 레벨 언어와 맞춤형 데이터 구조가 얼마나 큰 이점을 제공할 수 있는지를 실증적으로 보여준다. 향후 연구에서는 장애 복구 메커니즘을 경량화하거나, Spark와의 하이브리드 모델(예: Spark의 DAG 스케줄링에 MPI 기반 연산 엔진을 연결) 등을 탐색하면 실용성을 더욱 높일 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기