연구자를 위한 TF Replicator 분산 머신러닝 프레임워크
초록
TF‑Replicator는 TensorFlow 위에 구축된 고수준 추상화로, 데이터‑병렬·모델‑병렬 학습을 손쉽게 구현하고, CPU·GPU·TPU 클러스터에 동기·비동기 방식으로 배포할 수 있다. ResNet‑50, SN‑GAN, D4PG 등 세 가지 서로 다른 모델을 실험해 확장성·성능을 검증하였다.
상세 분석
TF‑Replicator는 기존 TensorFlow의 저수준 복제 메커니즘을 추상화하여 연구자가 분산 시스템에 대한 깊은 이해 없이도 복잡한 학습 파이프라인을 구현하도록 설계되었다. 핵심 아이디어는 “replica”라는 개념으로, 하나의 replica는 입력 파이프라인(input fn)과 단계 연산(step fn)으로 구성된다. 사용자는 단일 머신에서와 동일한 방식으로 모델과 학습 루프를 정의하고, TF‑Replicator가 이를 자동으로 여러 디바이스에 복제한다.
복제 전략은 크게 두 가지로 나뉜다. 첫째, in‑graph replication은 하나의 거대한 그래프 안에 모든 replica를 배치하고, 마스터가 동기식으로 실행한다. 이는 GPU·TPU와 같이 메모리와 연산 자원이 풍부한 환경에서 높은 효율을 제공한다. 둘째, between‑graph replication은 각 워커가 독립적인 그래프를 실행하고 파라미터 서버를 통해 변수들을 공유한다. 이 방식은 비동기 SGD와 같은 로킹‑프리 학습에 적합하며, 워커 장애 시에도 전체 학습이 지속될 수 있는 내 fault‑tolerance 특성을 갖는다.
TF‑Replicator는 MultiGpuReplicator, MultiWorkerReplicator, TpuReplicator, MultiWorkerAsyncReplicator 등 네 가지 구현체를 제공한다. 각각은 지원하는 디바이스 수, 워커 수, 복제 패턴을 명시적으로 정의한다. 예를 들어, TpuReplicator는 8코어 TPU를 하나의 워커로 간주하고, in‑graph 복제로 동기식 학습을 수행한다. 반면, MultiWorkerAsyncReplicator는 전통적인 파라미터 서버 구조를 사용해 대규모 클러스터에서 비동기 학습을 가능하게 한다.
모델 병렬성을 지원하기 위해 TF‑Replicator는 logical_device 함수를 도입한다. 이는 step fn 내부에서 논리적 디바이스 ID를 전역 디바이스 컨텍스트에 매핑함으로써, 하나의 replica가 여러 물리 디바이스에 걸쳐 연산을 분산시킬 수 있게 한다. 이를 통해 메모리 한계가 있는 대형 모델도 손쉽게 구현 가능하다.
통신 측면에서는 MPI 스타일의 원시 연산인 all_reduce, all_sum, all_gather, broadcast, map_reduce, map_gather 등을 제공한다. 특히 all_sum을 활용한 wrap_optimizer는 Horovod의 DistributedOptimizer와 유사하게 각 replica에서 계산된 그래디언트를 평균화한다. 이러한 원시 연산은 교차‑replica 배치 정규화와 같이 기존 TensorFlow API만으로는 구현하기 어려운 고급 기법을 지원한다.
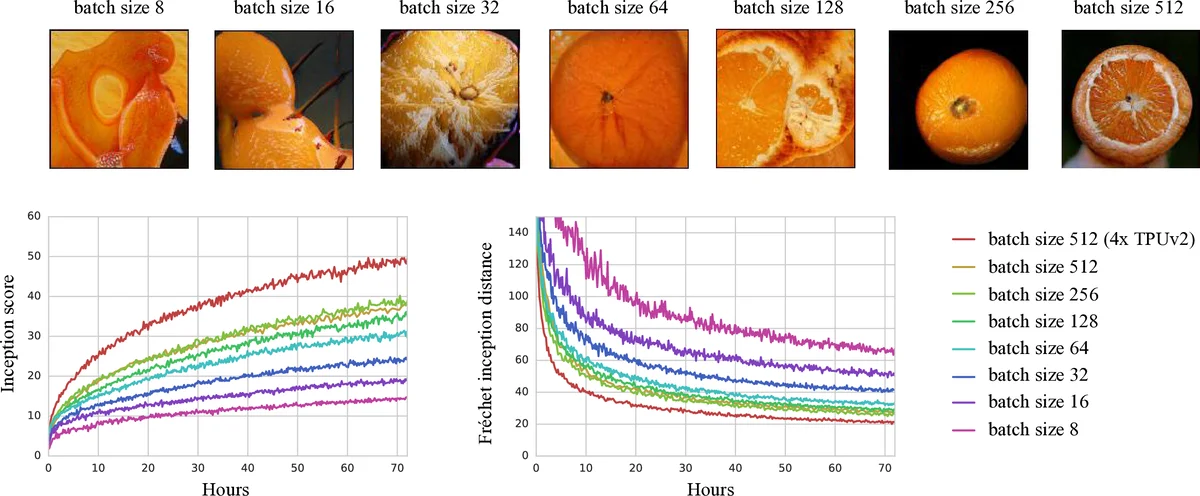
논문에서는 세 가지 베이스라인을 통해 TF‑Replicator의 범용성과 확장성을 실증하였다. (1) ResNet‑50을 ImageNet 데이터셋에 적용해 GPU와 TPU 클러스터에서 0.9 × 배속 향상을 기록했으며, (2) SN‑GAN을 이용한 클래스‑조건 이미지 생성에서는 8‑GPU 환경에서 1.8배, 8‑TPU 코어에서 2.3배의 학습 속도 향상을 보였다. (3) D4PG 강화학습 에이전트는 연속 제어 태스크에서 32‑GPU 클러스터와 64‑TPU 코어 환경에서 각각 1.5배, 2.0배의 스루풋을 달성했다. 모든 실험에서 기존 TensorFlow Estimator나 Horovod 기반 구현 대비 코드 복잡도가 크게 감소했으며, 사용자 입장에서는 분산 시스템 설정을 거의 신경 쓰지 않아도 되는 수준이었다.
전반적으로 TF‑Replicator는 연구자 중심의 설계 철학을 바탕으로, 복잡한 분산 학습 파이프라인을 단순화하면서도 최신 하드웨어와 다양한 학습 패러다임을 포괄한다는 점에서 머신러닝 연구 인프라의 중요한 진보라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기