다중 스트림 CNN과 시간 주의 메커니즘을 활용한 환경 소리 분류
** 본 논문은 원시 파형, STFT 스펙트로그램, 델타 스펙트로그램을 입력으로 하는 3‑스트림 CNN에 에너지 변화를 기반으로 한 시간 주의(attention) 모듈을 결합하고, 불확실성을 고려한 결정 융합(decision fusion) 방식을 도입한다. ESC‑10, ESC‑50, DCASE 2016 데이터셋에서 별도의 구조 변경 없이 최고 수준의 정확도를 달성함으로써 모델의 일반화 가능성을 입증한다. **
저자: Xinyu Li, Venkata Chebiyyam, Katrin Kirchhoff
**
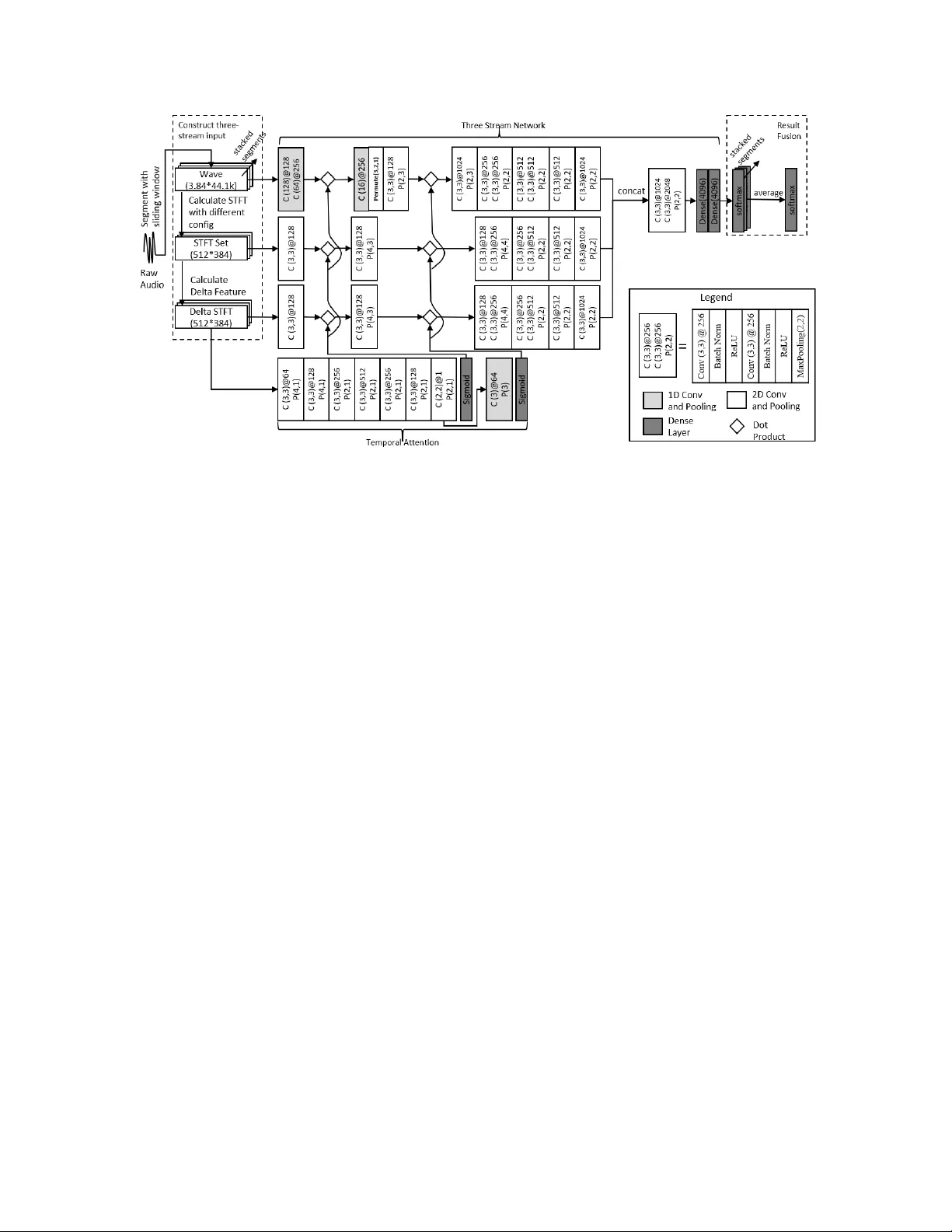
본 논문은 환경 소리 분류(ESC) 분야에서 흔히 발생하는 두 가지 문제—데이터셋 간 일반화 어려움과 소리마다 상이한 시간적 구조—를 동시에 해결하기 위한 새로운 모델을 제안한다. 모델은 세 가지 기본 오디오 표현을 각각 독립적인 스트림으로 입력받는다. 첫 번째 스트림은 원시 파형으로, 시간 도메인에서 직접 1D 컨볼루션을 거쳐 2D 형태의 특징 맵으로 변환한다. 두 번째와 세 번째 스트림은 STFT 스펙트로그램과 그에 대한 델타(시간 미분) 스펙트로그램이다. STFT는 32, 128, 1024점 FFT를 사용해 서로 다른 주파수·시간 해상도를 확보하고, 각각을 512×384 크기로 정규화한 뒤 스택한다. 델타 스펙트로그램은 5프레임 윈도우를 이용해 에너지 변화를 강조한다.
네트워크 구조는 기존 EnvNet을 기반으로 하며, 1D 컨볼루션을 통해 파형의 차원을 급격히 축소하고, 2D 컨볼루션(3×3 필터, 배치 정규화, ReLU)으로 STFT와 델타 스펙트로그램을 처리한다. 모든 스트림은 동일한 풀링 단계(시간 축에 동일하게 적용)를 거치므로, 최종 특징 맵은 시간 축이 완전히 동기화된 상태가 된다. 이렇게 정렬된 특징은 시간 차원에서 단순히 concatenate하여 하나의 통합 표현을 만든다.
시간 주의(attention) 메커니즘은 기존 RNN 기반 주의와 달리 CNN 레이어와 직접 결합된다. 저자는 델타 스펙트로그램을 입력으로 사용해 1D 컨볼루션·풀링을 반복해 피처 차원을 1로 만든 뒤, 시간 차원에 대해 다시 풀링해 (1×T) 형태의 가중치 벡터 A를 얻는다. 이 벡터는 세 스트림 모두에 동일하게 적용되며, 각 레이어의 출력 C에 대해 점곱(C·A) 연산을 수행한다. 결과적으로 중요한 시간 구간은 강조되고, 배경 잡음이나 무음 구간은 억제된다. 시각화 실험에서는 주기적 소리(시계 똑딱임)에서는 주기적인 가중치 패턴이, 연속적 소리(바다 파도)에서는 지속적인 가중치가, 비주기적 소리(개 짖음)에서는 핵심 이벤트에만 높은 가중치가 부여되는 것을 확인했다.
다음으로 제안된 “불확실성을 고려한 결정 융합”은 고정 길이 입력을 요구하는 CNN의 한계를 보완한다. 긴 오디오를 3.84초 길이의 윈도우로 나누어 각각 예측하고, 최종 클래스 확률은 각 윈도우의 softmax 출력을 평균한다. 여기서 저자는 훈련 단계에 백색 잡음 구간을 삽입하고, 이 구간에 대해 모든 클래스에 균등한 확률 분포를 목표로 학습시킨다. 이렇게 하면 모델이 의미 없는 구간에 대해 높은 엔트로피 출력을 내도록 강제되어, 실제 테스트 시 잡음이나 침묵 구간이 전체 예측을 왜곡하는 것을 방지한다.
데이터 증강은 “between‑class” 믹스업 방식을 변형한 형태로 수행된다. 두 샘플을 무작위 비율 r로 선형 혼합하고, 시작 시점을 랜덤하게 선택해 3‑채널 입력 전체에 적용한다. 이 방식은 기존의 신호 레벨 기반 믹스업보다 약 20배 빠르고, 3D 입력에도 자연스럽게 적용 가능하다. 증강은 매 epoch마다 새롭게 수행돼 과적합을 효과적으로 억제한다.
실험은 세 개의 널리 사용되는 데이터셋—ESC‑10, ESC‑50, DCASE 2016—에서 수행되었다. ESC‑10은 10개의 클래스를, ESC‑50은 50개의 클래스를, DCASE는 4개의 환경 씬을 포함한다. 각 데이터셋에 대해 5‑fold 교차 검증(ESC‑10/50) 혹은 공식 트레인/테스트 분할(DCASE)을 사용했다. 모델은 Keras/TensorFlow 기반으로 구현됐으며, Adam 옵티마이저(초기 학습률 0.001, 100 epoch마다 10배 감소)를 사용하고 손실 함수로는 평균 절대 오차(MAE)를 채택했다.
성능 비교 결과, 제안 모델은 기존 최고 기록을 능가하거나 동등한 정확도를 달성했다. ESC‑10에서는 0.942(최고), ESC‑50에서는 0.882(최고), DCASE에서는 0.840(최고) 를 기록했으며, 이는 동일한 네트워크 구조와 전처리 파이프라인을 유지하면서도 데이터셋마다 별도 튜닝이 필요 없다는 점에서 큰 의미가 있다. Ablation study에서는 (1) 세 스트림 모두 사용했을 때 가장 높은 정확도, (2) 시간 주의가 모든 데이터셋에서 평균 1~2%p 상승, (3) 결정 융합이 약 2.5%p 향상, (4) 불확실성 기반 잡음 삽입이 추가 1%p 향상을 제공함을 확인했다. 또한, 각 스트림을 하나씩 제외했을 때 성능이 현저히 떨어지는 것을 통해 각 입력 형태가 상호 보완적인 역할을 함을 입증했다.
결론적으로, 이 논문은 “단순한 기본 오디오 표현 + CNN 기반 시간 주의 + 불확실성 기반 윈도우 융합”이라는 세 가지 핵심 요소를 결합해, 복잡한 전처리나 특수한 네트워크 설계 없이도 다양한 ESC 과제에 강인하고 일반화 가능한 성능을 제공한다는 점에서 학술적·실용적 기여가 크다. 향후 연구에서는 더 큰 규모의 Audioset 같은 데이터셋에 적용하거나, 겹치는 소리(다중 이벤트) 처리를 위한 멀티라벨 확장 및 실시간 인퍼런스 최적화가 기대된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기