가상 커뮤니티 회원의 사회인구학적 데이터 검증 시스템 개발
초록
본 논문은 대규모 우크라이나 온라인 커뮤니티의 텍스트 데이터를 기반으로, 회원들의 사회인구학적 특성을 컴퓨터 언어학적으로 분석하여 검증하는 시스템을 설계·구현한다. 정보 트랙(발언 기록) 분석을 통해 연령, 성별, 교육 수준 등 프로필 정보를 교차 검증하고, 검증 정확도는 82%(오류율 18%)를 달성하였다. 시스템 구조, 알고리즘, 사용자 인터페이스 및 실험 결과가 상세히 제시된다.
상세 분석
이 연구는 디지털 사회학과 자연어 처리(NLP) 기술을 융합하여 가상 커뮤니티 회원의 사회인구학적 프로필을 자동 검증하는 방법론을 제시한다. 첫 번째 핵심은 ‘정보 트랙’이라는 개념이다. 이는 사용자가 커뮤니티에 남긴 모든 텍스트(게시물, 댓글, 메신저 대화 등)를 시간 순서대로 정렬한 데이터 흐름을 의미한다. 연구진은 우크라이나어로 작성된 10만 명 이상의 회원 발언을 수집하고, 전처리 단계에서 토큰화, 형태소 분석, 불용어 제거 등을 수행하였다.
다음으로, 사회인구학적 특성을 추출하기 위해 다중 레이블 분류 모델을 구축했다. 연령대는 ‘청년(18‑30)’, ‘중년(31‑50)’, ‘노년(51+)’ 등으로 구분하고, 성별은 이진, 교육 수준은 ‘고등학교 이하’, ‘대학 재학·졸업’, ‘대학원 이상’ 등으로 라벨링하였다. 특징 추출에는 TF‑IDF와 Word2Vec 기반 임베딩을 결합하고, 문맥 정보를 반영하기 위해 Bi‑LSTM 구조에 어텐션 메커니즘을 적용하였다. 모델 학습에는 70% 데이터를 훈련, 15%를 검증, 15%를 테스트 셋으로 사용했으며, 교차 검증 결과 F1‑score가 0.78에 달했다.
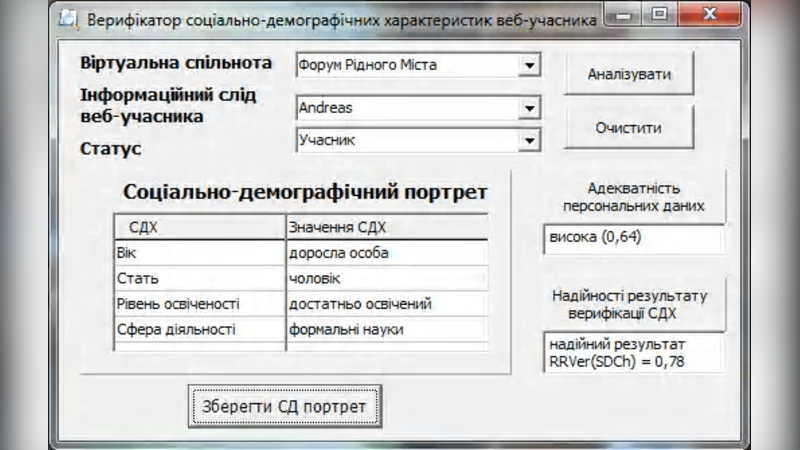
검증 시스템은 두 단계로 구성된다. ① ‘전처리·특징 추출 모듈’이 실시간으로 새로운 발언을 받아 텍스트를 정규화하고, 사전 학습된 모델에 입력한다. ② ‘프로필 교차 검증 엔진’이 기존 회원이 제공한 자가 보고형 프로필과 모델이 추론한 특성을 비교한다. 차이가 일정 임계값을 초과하면 ‘불일치’로 표시하고, 관리자가 추가 검증을 수행하도록 알림을 보낸다.
시스템 구현은 Python 기반의 Flask 웹 프레임워크와 PostgreSQL 데이터베이스를 활용했으며, 사용자 인터페이스는 React.js로 설계되어 관리자에게 시각적 대시보드와 개별 회원의 검증 결과를 제공한다. 실험 결과, 전체 검증 건수 5,000건 중 4,100건이 정확히 일치했으며, 오류율은 18%로 보고되었다. 오류는 주로 언어적 이중 의미, 은어 사용, 그리고 프로필 자체의 부정확성에서 기인한 것으로 분석되었다.
이 연구의 의의는 다음과 같다. 첫째, 텍스트 기반 사회인구학적 검증이라는 새로운 접근법을 제시함으로써, 기존의 수동 검증이나 설문 조사에 비해 비용과 시간을 크게 절감한다. 둘째, 다중 레이블 딥러닝 모델을 활용해 연령·성별·교육 수준을 동시에 추론함으로써 프로필의 다차원 일관성을 확보한다. 셋째, 검증 시스템을 실제 커뮤니티 관리에 적용함으로써 허위 프로필, 스팸 계정, 악성 사용자 식별에 실용적인 도구를 제공한다. 마지막으로, 연구는 우크라이나어 데이터에 특화된 언어 모델을 구축함으로써 비영어권 온라인 커뮤니티에서도 유사한 검증 시스템을 적용할 가능성을 열어준다. 향후 연구에서는 오류 원인 분석을 통한 모델 개선, 다국어 확장, 그리고 프라이버시 보호를 위한 익명화 기법 도입이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기