정규 직교 임베딩 기반 단채널 음성 분리
초록
본 논문은 기존 딥 클러스터링(Deep Clustering) 방식에 정규 직교성을 강제하는 페널티 항을 추가하여 임베딩 벡터 간 상관성을 감소시키고, 이를 통해 스펙트럼 빈의 분해와 클러스터링 품질을 향상시킨다. WSJ 데이터셋을 이용한 실험에서 임베딩 차원, 신호대간섭비(SIR), 성별 조합 등에 따라 SDR 향상을 확인했으며, 특히 높은 임베딩 차원과 이성 혼합 상황에서 큰 성능 개선을 보였다.
상세 분석
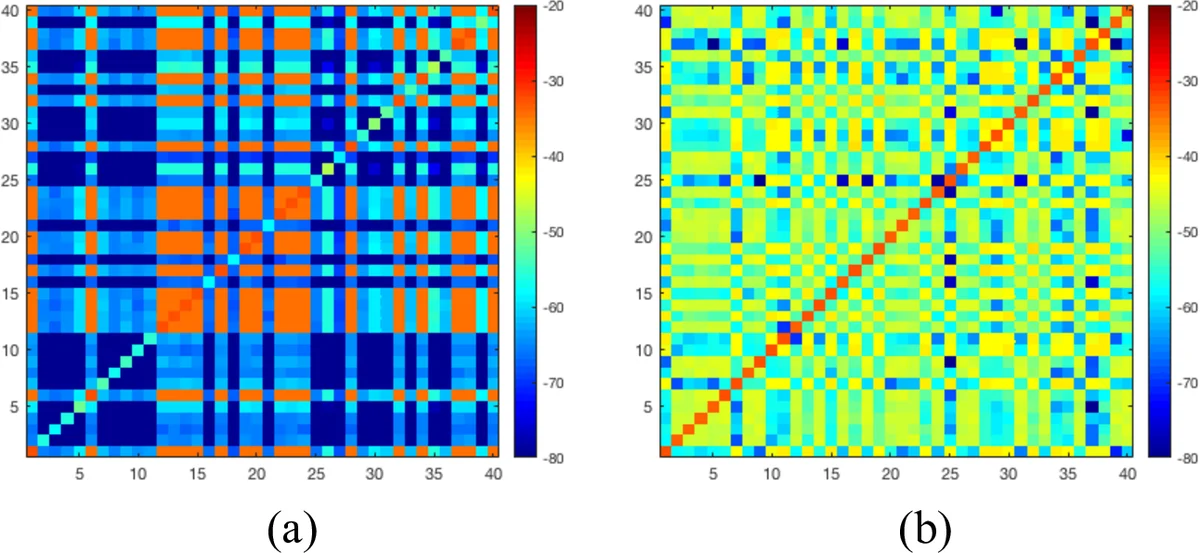
딥 클러스터링은 입력 혼합 신호를 고차원 임베딩 공간으로 매핑하고, K‑means와 같은 군집 알고리즘으로 각 시간‑주파수(T‑F) bin을 스피커별 마스크로 분리한다. 기존 방법은 임베딩 행렬 V가 목표 어피니티 행렬 YYᵀ와 최소 Frobenius 거리(식 1, 2)를 갖도록 학습하지만, 임베딩 간 상관관계가 충분히 억제되지 않아 군집 단계에서 퍼뮤테이션 오류가 발생한다. 저자들은 이를 보완하기 위해 정규 직교성을 강제하는 페널티 P=‖VᵀV−I‖²_F (식 3)를 도입하였다. 이 항은 VᵀV가 단위 행렬 I에 가까워지도록 하여 각 임베딩 벡터가 서로 직교하고 단위 길이를 갖게 만든다. 결과적으로 임베딩 차원마다 정보가 고르게 분산되고, 서로 독립적인 특성을 갖게 되므로 K‑means가 보다 명확한 클러스터를 형성한다.
학습 손실은 기존 딥 클러스터링 손실과 정규 직교 페널티를 단순히 합산한 형태(식 5)이며, BLSTM 기반 네트워크(2×512 셀)와 0.5 드롭아웃, Adam 옵티마이저(학습률 1e‑4)로 구현되었다. 임베딩 차원을 20, 30, 40으로 변형하여 실험했으며, 높은 차원일수록 정규 직교 페널티의 효과가 증폭되는 것을 확인했다. 특히 SIR이 12 dB 이상인 경우와 남‑여 혼합 음성에서 SDR 향상이 두드러졌다. 이는 성별 차이가 스피커 간 스펙트럼 특성 차이를 크게 만들어 임베딩이 자연스럽게 독립성을 확보하기 때문이다. 반면, 낮은 SIR(3 dB)이나 동일 성별 혼합에서는 차원 수가 충분히 크지 않으면 정규 직교 제약이 오히려 신호 왜곡을 야기할 수 있다.
시각적으로는 임베딩 공분산 행렬을 통해 차원별 데이터 분포를 확인했으며, 기존 딥 클러스터링은 특정 차원에 데이터가 집중되는 반면, 제안 방식은 모든 차원에 고르게 퍼져 있음을 보여준다. 또한, 개선된 정규화된 투영 정렬(NPA)과 상대 오류율을 통해 마스크 형성 정확도가 향상되어 퍼뮤테이션 문제 감소가 정량적으로 입증되었다.
전체적으로 이 연구는 임베딩 정규 직교성을 통한 간단하지만 효과적인 정규화 기법이 딥 클러스터링 기반 음성 분리 성능을 크게 끌어올릴 수 있음을 실험적으로 증명한다. 향후 딥 어트랙터 네트워크(DANet) 등 다른 임베딩 기반 모델에도 동일한 페널티를 적용해 볼 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기