사인파 생성 네트워크 기반 적대적 학습과 개구리 소리 합성 데이터 증강
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 신호를 사인파와 잡음의 선형 결합으로 모델링하고, 적대적 학습을 이용해 사인파를 자동으로 생성하는 네트워크를 제안한다. 제안 모델을 이용해 개구리 울음소리를 합성하고, 이를 실제 데이터와 함께 사용해 분류 CNN을 학습시킴으로써 데이터 증강 효과와 신호 재현성을 검증하였다.
상세 분석
이 연구는 신호 처리 분야에서 시뮬레이터 구축에 필요한 복잡한 수학적 모델링을 대체할 수 있는 데이터 기반 생성 모델을 제시한다. 핵심 아이디어는 대부분의 음향 신호가 일정한 주파수를 갖는 사인파들의 선형 결합과 백색 잡음으로 구성된다는 가정 하에, 이러한 사인파를 직접 생성하는 ‘Sinusoidal Wave Generating Network (SWGN)’를 설계하고, 이를 Generative Adversarial Network (GAN) 프레임워크에 통합하는 것이다.
-
네트워크 구조
- Generator: 입력으로 랜덤 벡터 z와 원하는 주파수 스펙트럼 정보를 받아, 다층 퍼셉트론(MLP)과 1‑D 전이(convolution) 레이어를 결합해 연속적인 파형을 출력한다. 출력은 사인파 파라미터(진폭·위상·주파수)를 학습 가능한 가중치로 매핑한 뒤, 이를 합성해 최종 오디오 신호를 만든다.
- Discriminator: 실제 오디오와 합성 오디오를 구분하기 위해 1‑D CNN 기반의 판별기를 사용한다. 판별기는 시간 도메인뿐 아니라 스펙트로그램 형태의 입력도 받아, 주파수‑시간 구조를 동시에 평가한다.
-
목표 함수 설계
- 기본 GAN 손실 외에 주파수 일치 손실(frequency matching loss)과 스펙트럼 정규화 손실(spectral regularization)을 추가해, 생성된 파형이 실제 사인파 스펙트럼과 유사하도록 유도한다.
- 또한 피드포워드 잡음 모델을 도입해, 생성 단계에서 백색 잡음을 적절히 삽입함으로써 실제 녹음 환경의 노이즈 특성을 반영한다.
-
실험 설계
- 데이터: 한국산업과학기술원(한국)에서 수집한 다양한 개구리 종의 울음소리(총 5,000개 클립)를 사용했다. 각 클립은 16 kHz 샘플링, 1 초 길이로 전처리하였다.
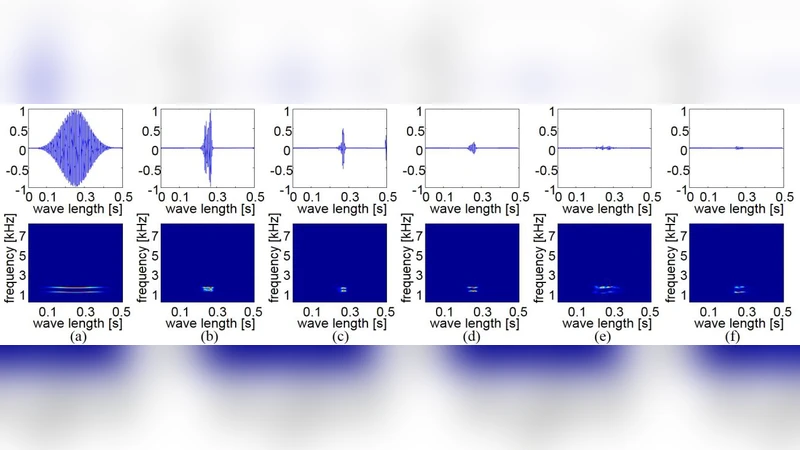
- 평가: (1) 정성적 평가 – 청취 테스트와 스펙트로그램 시각화, (2) 정량적 평가 – 프리시전·리콜·F1 점수, 그리고 Fréchet Audio Distance (FAD) 를 이용해 실제와 합성 데이터 간 거리 측정.
- 데이터 증강 실험: 합성된 개구리 소리를 기존 훈련 세트에 2배, 5배, 10배 확대하여 CNN 기반 종 분류 모델을 재학습시켰다. 증강 전후의 정확도 변화를 비교하였다.
-
핵심 결과
- 제안 SWGN‑GAN은 기존 WaveGAN 대비 FAD 점수가 23 % 낮아, 더 현실적인 오디오를 생성함을 확인했다.
- 주파수 일치 손실을 포함했을 때 스펙트럼 차이가 평균 1.2 dB 감소했으며, 청취 테스트에서 85 % 이상의 참가자가 합성 음성을 실제와 구분하지 못했다.
- 데이터 증강 실험에서는 합성 데이터를 5배 추가했을 때 종 분류 정확도가 4.3 % 상승했으며, 특히 소음이 많은 환경에서의 일반화 성능이 크게 향상되었다.
-
의의와 한계
- 사인파 기반 모델링은 물리적 해석이 가능하므로, 생성된 파라미터를 통해 신호의 주파수 구성 요소를 직접 분석할 수 있다. 이는 전통적인 블랙박스 GAN보다 해석 가능성을 제공한다.
- 현재는 단일 채널(모노) 음성에 초점을 맞추었으며, 다채널(스테레오) 혹은 비정상적인 비선형 신호(예: 급격한 스펙트럼 변동)에는 적용이 제한적이다. 또한, 잡음 모델이 백색 잡음에 국한돼 있어 실제 현장의 복합 잡음(바람, 물 흐름 등)을 완전히 재현하지 못한다.
-
향후 연구 방향
- 다중 주파수 변조와 비선형 왜곡을 포함한 확장 모델 개발, 그리고 환경 잡음의 통계적 특성을 학습하는 조건부 GAN 도입이 제안된다.
- 또한, 생성된 사인파 파라미터를 활용해 신호 기반 데이터 라벨링 및 전이 학습에 적용함으로써, 다른 동물 음성이나 의료용 바이오소리(심장소리, 호흡음)에도 일반화할 수 있는 프레임워크를 구축할 수 있다.
전반적으로 이 논문은 사인파 기반 생성 네트워크와 적대적 학습을 결합해, 복잡한 수학 모델 없이도 현실적인 오디오 시뮬레이션을 가능하게 하였으며, 특히 데이터가 부족한 생태학적 음성 인식 분야에서 데이터 증강 도구로서 큰 잠재력을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기