프로젝티브 분해와 스케일 동등성: 행·열 정규화의 새로운 패러다임
초록
본 논문은 행과 열 모두에 동일한 정규화 전략을 적용하는 ‘프로젝티브 분해’를 제안한다. 행·열 스케일링 팩터와 스케일‑정규화 행렬을 분리함으로써, 동일한 스케일‑정규화 행렬의 다양한 스케일링이 하나의 동등 클래스(equivalence class)를 이루고, 그 중 대표적인 ‘스케일‑불변 형태’를 정의한다. 이 방식은 비율 척도 데이터의 상대 비율을 보존하면서도 행·열의 스케일 효과를 동시에 보정한다는 점에서 전통적인 z‑변환과 차별화된다.
상세 분석
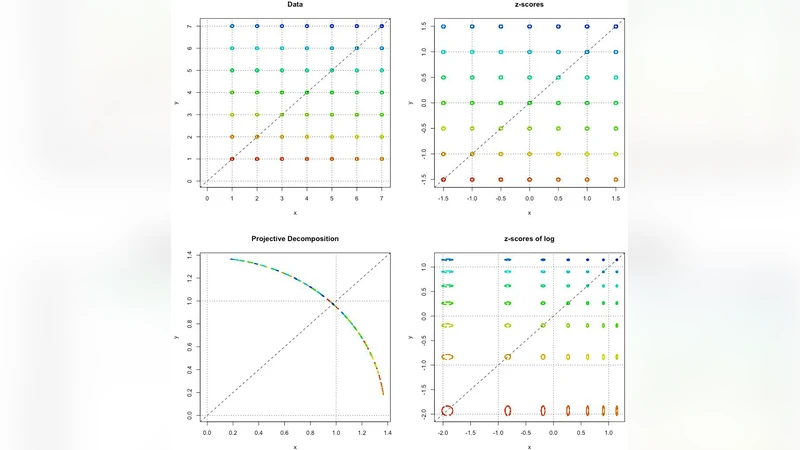
프로젝티브 분해는 데이터 행렬 A 를 세 요소 D_r (행 스케일링 대각 행렬), D_c (열 스케일링 대각 행렬), S (스케일‑정규화 행렬) 로 분해하는 A = D_r S D_c 형태를 제시한다. 여기서 D_r 와 D_c 는 양의 실수 대각 원소만을 갖으며, 각각 행과 열의 절대 규모를 흡수한다. 핵심은 S 가 “스케일‑불변”이라는 특성을 갖는다는 점이다. 즉, S 의 모든 원소 쌍 (i,j) 와 (k,l) 에 대해 S_{ij}/S_{kl} 비율이 원 행렬 A 의 동일 비율과 일치한다. 따라서 비율 척도 데이터(예: 화학 농도, 경제 지표 등)에서 관심 있는 상대 관계는 손실되지 않는다.
동등 클래스 개념은 S 에 임의의 양의 스칼라 α 를 곱하고, D_r, D_c 를 각각 α^{-1/2} 와 α^{-1/2} 로 조정하면 동일한 원본 행렬 A 를 재구성할 수 있음을 의미한다. 이는 행·열 스케일링이 서로 보완적으로 작용한다는 수학적 증명에 기반한다.
전통적인 z‑변환은 각 열을 평균 0, 분산 1 로 정규화하지만, 행 간 스케일 차이를 무시한다. 반면 프로젝티브 분해는 행과 열 모두에 대한 스케일을 명시적으로 분리하고, 비율을 보존하는 “상대적” 정규화를 제공한다. 이는 데이터 전처리 단계에서 “스케일 효과”가 분석 결과에 미치는 편향을 최소화한다는 실용적 장점을 가진다.
알고리즘적으로는 D_r 와 D_c 를 반복적인 행·열 평균 정규화(Iterative Proportional Fitting) 혹은 로그‑선형 모델 최적화로 추정한다. 수렴성은 행·열 총합이 양수이고, 행·열 차원이 충분히 크면 보장된다. 또한, 스케일‑불변 형태 S 는 고유값 분해, 주성분 분석, 군집화 등 기존 선형 방법에 그대로 적용 가능하므로, 기존 파이프라인을 크게 변경하지 않고도 정규화 효과를 얻을 수 있다.
결과적으로, 프로젝티브 분해는 “스케일‑정규화 + 비율 보존”이라는 두 축을 동시에 만족하는 새로운 행렬 정규화 프레임워크를 제공한다. 이는 특히 비율이 의미를 갖는 과학·공학 데이터셋에서, z‑변환이 놓치는 행·열 간 스케일 불균형을 교정하고, 분석의 해석 가능성을 높이는 데 기여한다.
댓글 및 학술 토론
Loading comments...
의견 남기기