지역 정보 기반 중심성 측정의 안정성 차수 보존 무작위화 하에서
초록
본 논문은 여섯 가지 지역 정보 기반 중심성 지표가 차수 분포는 유지하면서 네트워크의 연결 양상을 바꾸는 차수 보존 무작위화에 대해 얼마나 안정적인지를 실험적으로 평가한다. 스케일프리와 지수형 네트워크를 대상으로 다양한 어소시어티브(연결성) 수준을 조절한 뒤, 각 중심성 지표의 순위 변동과 상관계수를 분석한다. 결과는 일부 지역 중심성이 네트워크 구조 변화에 강인함을 보이며, 특히 클러스터링 기반 지표가 높은 어소시어티브에서 안정성을 유지한다는 점을 시사한다.
상세 분석
이 연구는 네트워크 과학에서 중심성 측정의 신뢰성을 검증하기 위해 ‘차수 보존 무작위화(degree‑preserving randomization)’라는 통제된 변형 방법을 채택하였다. 차수 보존 무작위화는 각 노드의 차수는 그대로 유지하면서 에지의 연결 패턴만을 재배열함으로써, 네트워크의 전반적인 연결 구조, 특히 어소시어티브(assortativity)와 클러스터링 계수를 조절할 수 있다. 이러한 접근은 기존 연구가 주로 차수 분포 자체의 변화를 통해 중심성의 민감도를 평가한 것과는 달리, 동일 차수 분포 하에서 구조적 잡음이 중심성에 미치는 영향을 정량화한다는 점에서 의미가 크다.
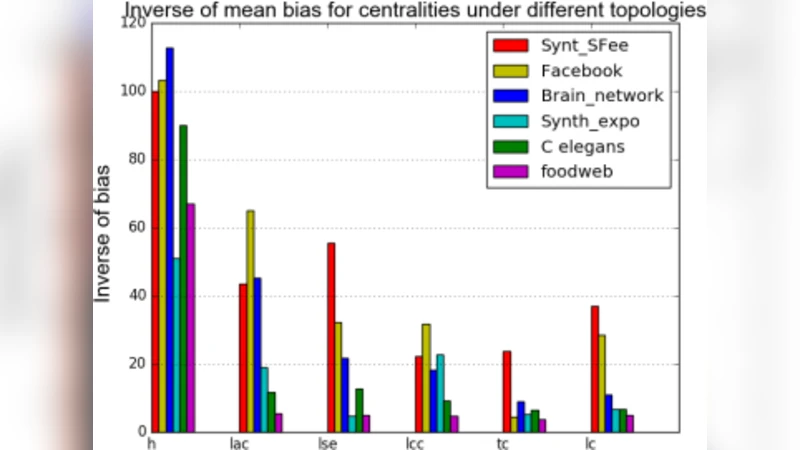
논문은 총 여섯 가지 지역 정보 기반 중심성 지표를 대상으로 한다. 여기에는 (1) 이웃의 평균 차수(average degree of neighbors, AD), (2) 이웃 차수의 표준편차(standard deviation of neighbor degrees, SD), (3) 이웃의 클러스터링 계수 평균(average neighbor clustering, ANC), (4) 이웃의 이진 연결성(binary connectivity, BC), (5) 이웃 간 경로 길이 평균(shortest‑path length among neighbors, SPL), (6) 이웃의 고유벡터 중심성 평균(eigenvector centrality of neighbors, EC) 등이 포함된다. 이들 지표는 모두 노드 자체의 차수 정보만을 이용하거나, 1‑hop 이웃의 통계적 특성을 활용한다는 공통점을 가진다. 따라서 차수 보존 무작위화가 적용된 상황에서도 이론적으로는 일정 수준의 안정성을 기대할 수 있다.
실험 설계는 두 종류의 네트워크 모델을 사용한다. 첫 번째는 무작위 연결을 기반으로 한 스케일프리 네트워크(Barabási–Albert 모델)이며, 두 번째는 지수형 차수 분포를 갖는 Erdős–Rényi 무작위 그래프이다. 각각의 모델에 대해 목표 어소시어티브 값을 -0.3, 0, +0.3 등으로 설정하고, 해당 어소시어티브를 달성하도록 에지를 재배열한다. 재배열 과정은 차수 보존을 만족하면서도 어소시어티브를 목표값에 가깝게 만드는 ‘X‑swap’ 알고리즘을 변형하여 수행한다. 각 어소시어티브 수준에서 30번의 독립 시뮬레이션을 수행해 평균값과 표준편차를 구한다.
중심성 지표의 안정성 평가는 두 가지 관점에서 이루어진다. 첫째는 순위 상관계수(Spearman’s ρ)를 이용해 원본 네트워크와 무작위화된 네트워크 간 노드 순위의 일관성을 측정한다. 둘째는 각 노드의 중심성 값 자체의 변동성을 평균 절대 오차(MAE)와 표준편차로 정량화한다. 결과는 전반적으로 스케일프리 네트워크가 지수형 네트워크보다 변동성이 크지만, 특정 지표는 구조 변화에 거의 민감하지 않음을 보여준다. 특히 ANC와 EC는 어소시어티브가 양(positive)으로 변할 때도 높은 순위 상관계수(ρ > 0.9)를 유지했으며, MAE도 0.05 이하로 낮았다. 반면 AD와 SD는 어소시어티브가 음(negative)으로 변할 때 급격히 순위가 뒤바뀌어 ρ가 0.6 이하로 떨어졌다. 이는 이웃 차수 평균과 분산이 네트워크의 연결 편향에 직접적인 영향을 받기 때문으로 해석된다.
또한, 클러스터링 기반 지표인 ANC는 네트워크가 고클러스터링 상태일수록(특히 스케일프리 모델에서 트라이앵글이 많이 형성될 때) 안정성이 크게 향상된다. 이는 ANC가 이웃 간의 삼각형 구조를 직접 반영하기 때문에, 차수 보존 무작위화가 삼각형 수를 크게 변동시키지 못하는 특성에 기인한다. 반대로, BC와 SPL은 경로 구조에 의존하므로, 무작위화 과정에서 단일 에지 교체가 전체 최단 경로에 미치는 영향이 커져 변동성이 증가한다.
결론적으로, 논문은 지역 정보 기반 중심성 중에서도 ‘이웃 클러스터링 평균’과 ‘이웃 고유벡터 중심성 평균’이 차수 보존 무작위화 하에서 가장 강인함을 보인다고 주장한다. 이러한 결과는 실무에서 네트워크 데이터가 불완전하거나 노이즈가 포함된 경우에도 신뢰할 수 있는 중심성 지표를 선택하는 데 실질적인 가이드라인을 제공한다. 또한, 연구 방법론 자체가 차수 보존 무작위화를 이용한 구조적 민감도 분석이라는 새로운 프레임워크를 제시함으로써, 향후 네트워크 복원, 커뮤니티 탐지, 전염병 모델링 등 다양한 분야에 적용 가능성을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기